
- Introduction
- Vectors
- Matrices
- Mechanics of matrix multiplication
- The identity matrix,I
- Geometric interpretation of matrix multiplication
- Commutation relationship between matrices
- Solving matrix equations 1
- Non-square matrices
- Special solutions
- Inverse matrix
- PA = LU
- Solving matrix equations 2
- Transpose of a matrix, AT
- Vector Spaces
- Projections
- Geometric Interpretation of the dot product
- Determinants
- Eigenvalues and eigenvectors
- Diagonalizing a matrix
Introduction
To quote Wikipedia, linear algebra is a branch of mathematics concerning linear equation such as

or linear functions such as

and their representations through matrices and vector spaces. (The  symbol means the variable on the left maps to the value on the right; I’ll try to stay away from this notation as much as possible).
symbol means the variable on the left maps to the value on the right; I’ll try to stay away from this notation as much as possible).
Vectors
A starting point for linear algebra is a discussion of vectors. Vectors can be defined in number of ways. The most general definition of a vector is that it’s an element of a vector space. A vector space,  , in turn, consists of vectors, a field and 2 operations, discussed below. A field, in general terms, is a commutative ring. However, there’s no reason to go into what a commutative ring is here. Instead, we’ll define a field,
, in turn, consists of vectors, a field and 2 operations, discussed below. A field, in general terms, is a commutative ring. However, there’s no reason to go into what a commutative ring is here. Instead, we’ll define a field,  , as the set of real and complex numbers such that adding, subtracting, multiplying or dividing these numbers yields another member of . The 2 operations alluded to above, more specifically, are
, as the set of real and complex numbers such that adding, subtracting, multiplying or dividing these numbers yields another member of . The 2 operations alluded to above, more specifically, are
- Vector addition is associative:
 for all
for all 
- There is a zero vector,
 , such that
, such that  for all
for all 
- Each vector,
 has a negative such that
has a negative such that  for all
for all - Scalar multiplication is associative:
 for any
for any  and
and - Scalar multiplication is distributive:
 and
and  for all
for all  and
and 
- Unitarity: There’s an identity element,
 such that
such that  for all
for all
That’s all pretty vague. Here’s a simpler definition that may be more familiar: a vector is an ordered collection of numbers that simultaneously specify a magnitude (represented graphically as length) and direction. The easiest vectors to visualize are vectors in space. The diagram below depicts such vectors.
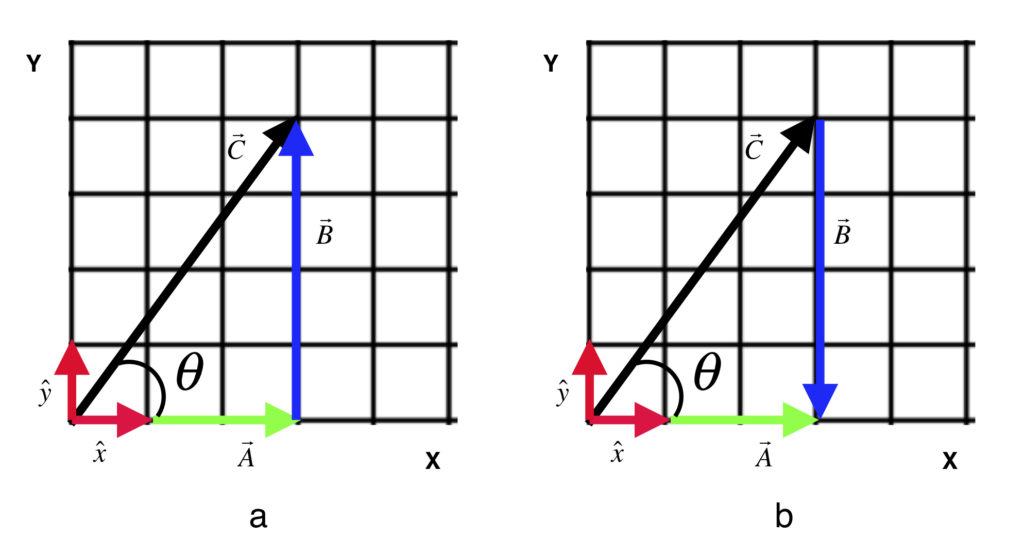
Figure 1 shows three vectors:  ,
,  and
and  .
.
- Vectors that have the same magnitude (length) and direction represent the same vector, no matter where they’re located in space. For example, from the figure 1a is the same vector whether its head starts at (0,0) and its tail ends at (0,3) or its head starts at (3,7) and its tail ends at (6,7).
- Graphically, we can add vectors together by placing them head to tail. In figure 1a, the head of is placed at the tail of to yield . This is equivalent to the equation
 .
. - Graphically, we can subtract one vector from another by reversing the direction of the vector to be subtracted and placing its new head at the tail of the vector from which it’s being subtracted. This is depicted in figure 1b and is equivalent to the equation
 .
.
Vectors can be represented algebraically as a linear combination of unit basis vectors.
- Basis vectors are vectors in a vector space, , such that all other elements of the vector space (i.e., vectors) can be written as a linear combination of these vectors.
- Unit basis vectors are basis vectors that are 1 unit in length.
- Orthonormal unit basis vectors are unit basis vectors whose dot product (described below) is zero. Orthonormal unit basis vectors are 1 unit in length and are oriented at
 to each other. This is true of the Cartesian coordinate system (the usual kind of graph paper you’re used to where axes are at to each other and units along both axes are equally spaced everywhere). This may not be true when other coordinate systems are used but that’s a discussion for another time. In figure 1, the unit basis vectors are represented by
to each other. This is true of the Cartesian coordinate system (the usual kind of graph paper you’re used to where axes are at to each other and units along both axes are equally spaced everywhere). This may not be true when other coordinate systems are used but that’s a discussion for another time. In figure 1, the unit basis vectors are represented by  and
and  . (Unit basis vectors, in general, are frequently represented with a little hat over the vector name).
. (Unit basis vectors, in general, are frequently represented with a little hat over the vector name). - In figure 1, , can be written as
 where
where  is called the x-coordinate of and
is called the x-coordinate of and  is called the y-coordinate of . In the above example, and are scalars (i.e., real or complex numbers). Specifically,
is called the y-coordinate of . In the above example, and are scalars (i.e., real or complex numbers). Specifically,  and
and  . On the other hand, and are vectors. Their magnitudes are both 1. points in the direction of the x-axis and points along the y-axis.
. On the other hand, and are vectors. Their magnitudes are both 1. points in the direction of the x-axis and points along the y-axis. - In figure 1, , can be written as
 where
where  is called the x-coordinate of and
is called the x-coordinate of and  is called the y-coordinate of . As in the case of , the coordinates of , and are scalars. Specifically,
is called the y-coordinate of . As in the case of , the coordinates of , and are scalars. Specifically,  and
and  .
. - To add vectors A and B, we add the components:
 .
. - This brings up another point: there are several ways that vectors are commonly represented
- as a bold letter (e.g.,
 )
) - with its components in angled brackets,
 , as we just noted
, as we just noted - with its components enclosed in brackets; if displayed horizontally, it’s called a row vector (e.g.,
 ); if displayed vertically, it’s called a column vector (e.g.,
); if displayed vertically, it’s called a column vector (e.g.,  ). There’s a difference between the two but that difference won’t be of concern for our immediate purposes so we’ll defer discussion about it for now
). There’s a difference between the two but that difference won’t be of concern for our immediate purposes so we’ll defer discussion about it for now - as a point in space, it’s coordinates being the coordinates of the vector
- as an arrow from the origin of a coordinate system to the point in space corresponding to the vector (as shown above)
- as a bold letter (e.g.,
- Likewise, to subtract from , we subtract components:
 .
.
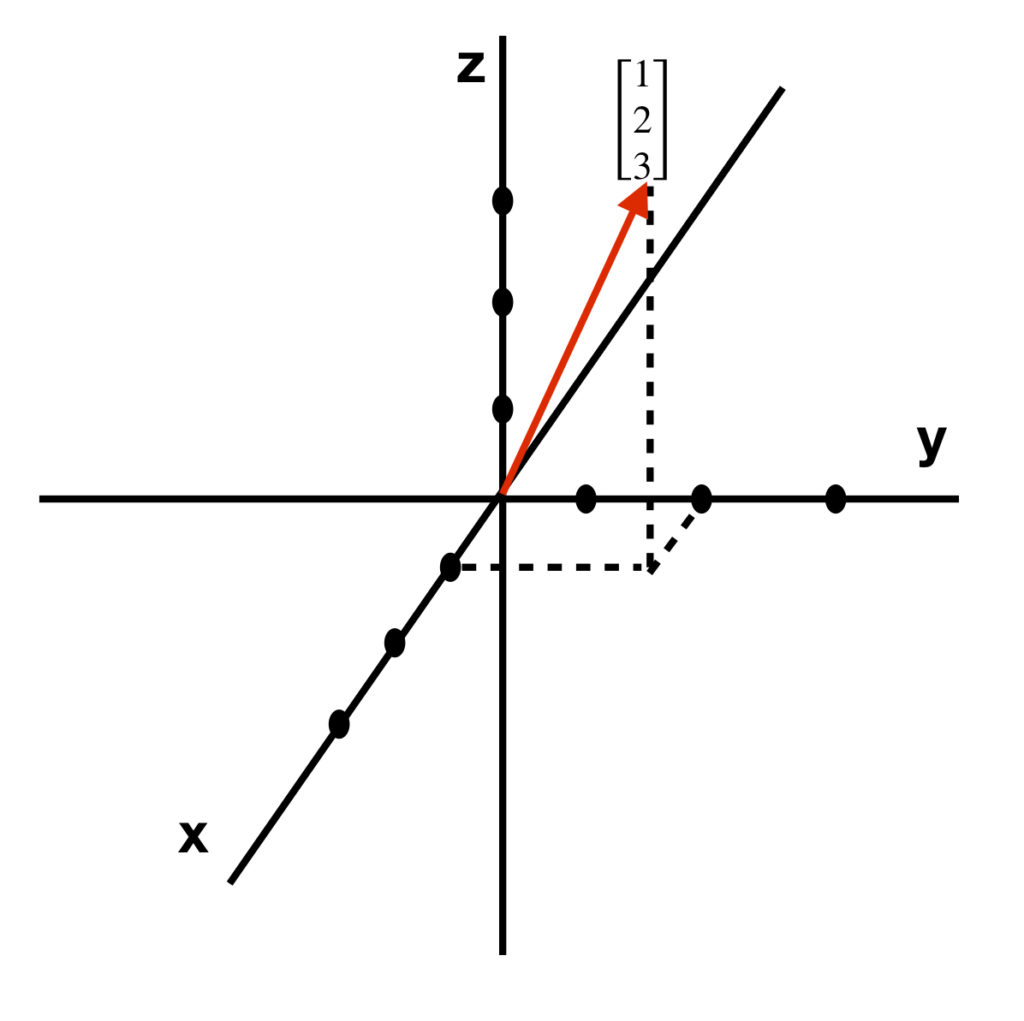
Figure 1 shows an example with 2-dimensional vectors. However, vectors can have as many dimensions as we want. The number of components that the vector contains represents the dimensionality of the vector. For example,  is a 3-dimensional vector that can be depicted graphically as follows:
is a 3-dimensional vector that can be depicted graphically as follows:
Linear combinations of vectors
Linear combinations of vectors are combinations of multiplication of vectors by a constant ((i.e.,  ) and addition. In the case of 3D vectors, (e.g.,
) and addition. In the case of 3D vectors, (e.g.,  ,
,  ,
,  ):
):
 represents a line.
represents a line.
 . If
. If  then
then  then
then  to
to  , we would get a line.
, we would get a line.
 fills a plane
fills a plane
 and
and  . Furthermore, let’s multiply by 3 sets of constants:
. Furthermore, let’s multiply by 3 sets of constants:  ,
,  and
and  . We get,
. We get,


 , and pair each value of
, and pair each value of  from
from  fills three-dimensional space.
fills three-dimensional space.
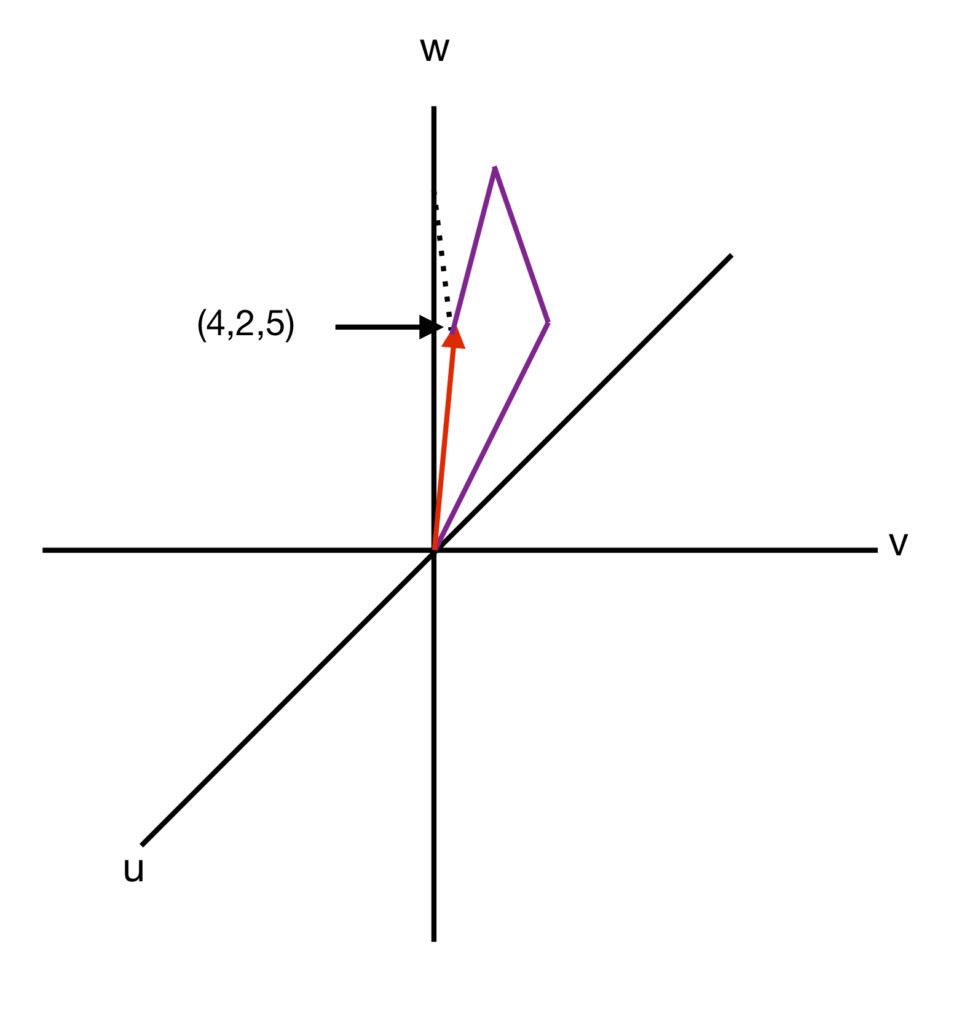

 yields an infinite number of points-every point in 3D space, in fact.
yields an infinite number of points-every point in 3D space, in fact.Vector lengths and dot products
Definition:
The dot product or inner product between two vectors  and
and  is depicted as
is depicted as  and yields a scalar:
and yields a scalar:

Example 1:  and
and 
 .
.
Example 2:  and
and  =(-1,2)
=(-1,2)
 .
.
Note that if the dot product of two vectors equals zero, the two vectors are said to be orthogonal. If we’re talking about 2D and 3D vectors in the usual Cartesian coordinate system that we’re used to, orthogonal means that they are perpendicular (i.e., the angle between them is  ).
).
If we’re dealing with 3D vectors like  and
and  then the dot product is
then the dot product is

For higher dimensional vectors (e.g. n-dimensional vectors  and
and  , the dot product is:
, the dot product is:

Dot product properities
Consider a scalar, and three vectors,  , and
, and  . The dot product for these vectors has the following properties:
. The dot product for these vectors has the following properties:
-
- Commutativity:

- Distributivity with addition:

- Distributivity with multiplication:

- Commutativity:
The proofs for these properties lie, basically, in computing the value of each side of each of the above equations and are quite tedious. Therefore, they will be left to the reader. However, examples of proofs of some of these properties can be found here (Khan Academy).
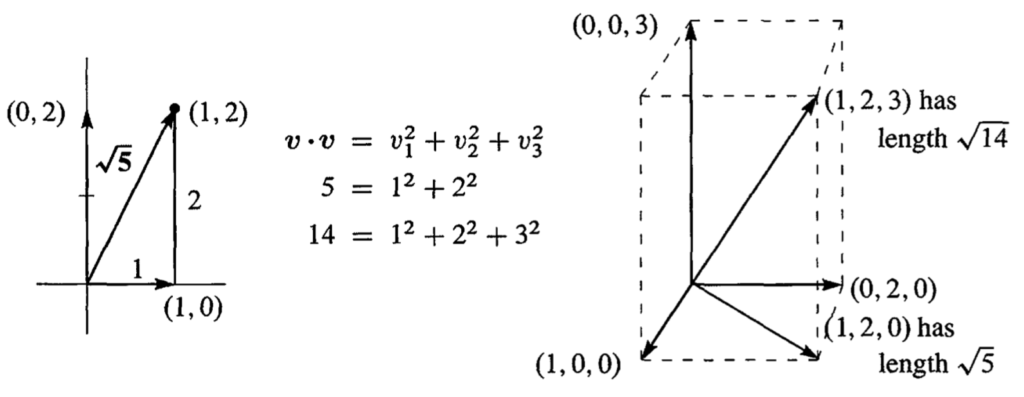
Vector lengths
The length of a vector  of a vector is the square root of
of a vector is the square root of  :
:

In two dimennsions, length is  . In three dimensions, it is
. In three dimensions, it is  . In four dimensions, it’s
. In four dimensions, it’s  , and so on. In these formulas, the subscripts represent components of the vector . This is just a statement of the Pythagorean theorem. A proof of why this is so can be found here.
, and so on. In these formulas, the subscripts represent components of the vector . This is just a statement of the Pythagorean theorem. A proof of why this is so can be found here.
Here are two examples taken directly from Strang’s textbook, p. 13:
Unit vectors
A unit vector is a vector that is one unit in length.
- To find the components of a unit vector in the direction of any vector, , divide the component,
 by the length of the vector,
by the length of the vector,  .
. - Unit vectors along the x and y axis of the Cartesian coordinate system that we’re used to are commonly denoted
 (for the x-axis) and
(for the x-axis) and  (for the y-axis).
(for the y-axis). - The components of a unit vector that makes an angle
 with the x-axis is
with the x-axis is  .
.
Here are examples taken from Strang’s textbook, p. 13:

Dot product formula using cosine
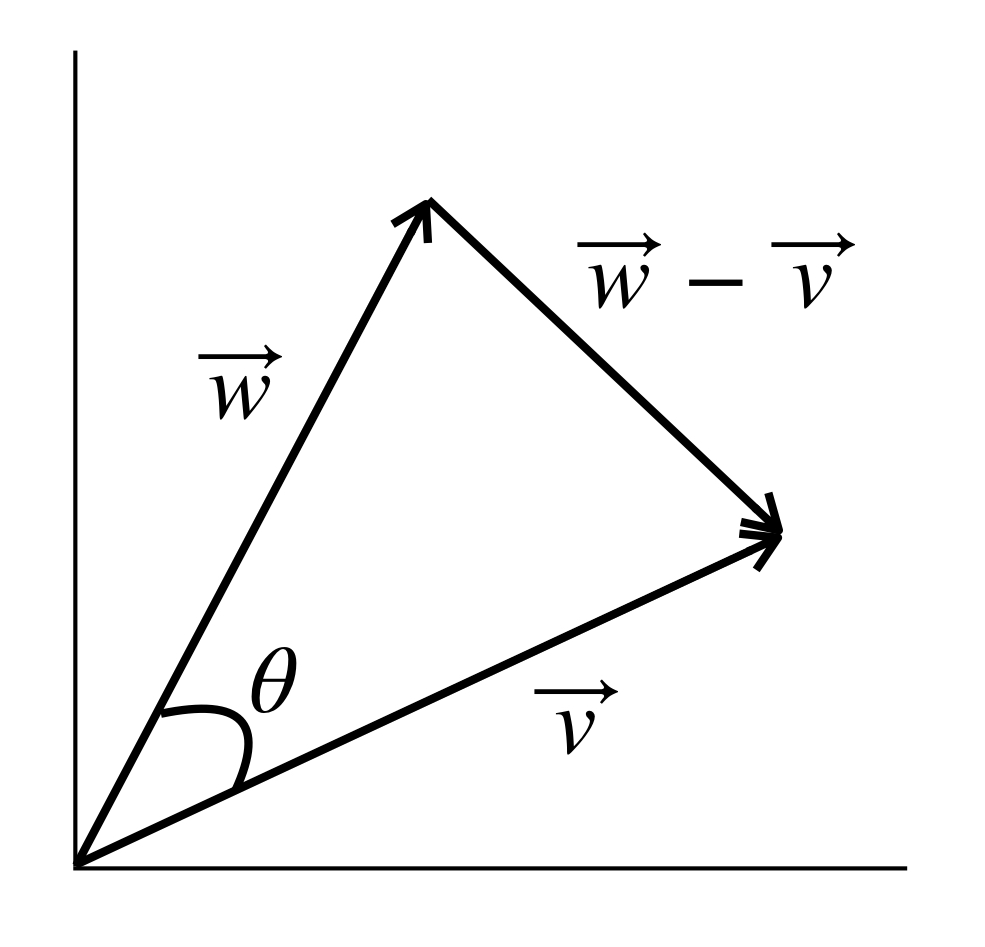
Referring to the diagram above, the law of cosines tells us that:

Using dot product properties, we can write the left-hand side of this equation as:

Substituting this into our original equation, we get:

Now subtract  and
and  from both sides of the equation. We have:
from both sides of the equation. We have:

Divide both sides of the equation by  . We are left with:
. We are left with:

and

Two important inequalities
There are two important inequalities that are a direct consequence of the dot product. They are:
- Schwarz inequality:

- Triangle inequality:

Proofs of these inequalities can be found at http://people.sju.edu/~pklingsb/cs.triang.pdf
Linear equations
Ultimately, linear algebra is about solving linear equations, especially systems of linear equations (i.e., multiple simultaneous linear equations). We call such equations linear equations because they can be represented as linear combinations of vectors. Here is a simple example borrowed from Dr. Gilbert Strang1

This set of equations can be looked at in two ways:
Row picture
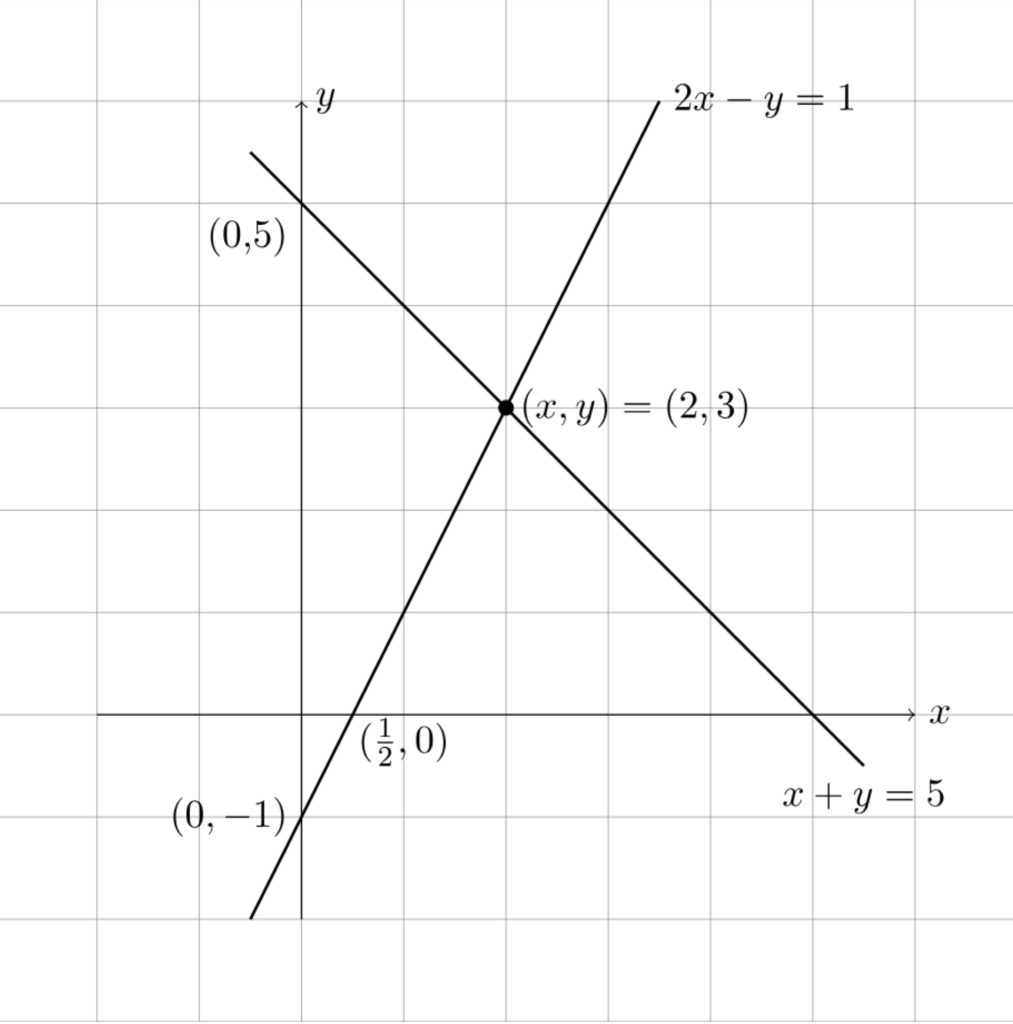
The equations  and
and  , which extend left to right across the page (like a row in a table) each represent a line. (To see why this is so, check out this review.) The point where the 2 lines intersect,
, which extend left to right across the page (like a row in a table) each represent a line. (To see why this is so, check out this review.) The point where the 2 lines intersect,  represents the solution to the system of equations.
represents the solution to the system of equations.
We can show that this is true algebraically. Start by adding equation 1 to equation 2:

Back substitute  into equation 2:
into equation 2:

So and  .
.
Column picture
Look at our system of equations:
This can be rewritten as
![\[ \begin{bmatrix} 2x\\x \end{bmatrix} + \begin{bmatrix} -y\\\,\,\,\,\,y \end{bmatrix} = \begin{bmatrix} 1\\5 \end{bmatrix}\]](https://www.samartigliere.com/wp-content/ql-cache/quicklatex.com-24859e379fc09c93ea2c9fdb0034ab1e_l3.png "Rendered by QuickLaTeX.com")
Factor out  and
and  :
:
![\[ x\begin{bmatrix} 2\\1 \end{bmatrix} + y\begin{bmatrix} -1\\\,\,\,\,\,1 \end{bmatrix} = \begin{bmatrix} 1\\5 \end{bmatrix}\]](https://www.samartigliere.com/wp-content/ql-cache/quicklatex.com-46fa9bbc65c69559ad6f45237d580b1e_l3.png "Rendered by QuickLaTeX.com")
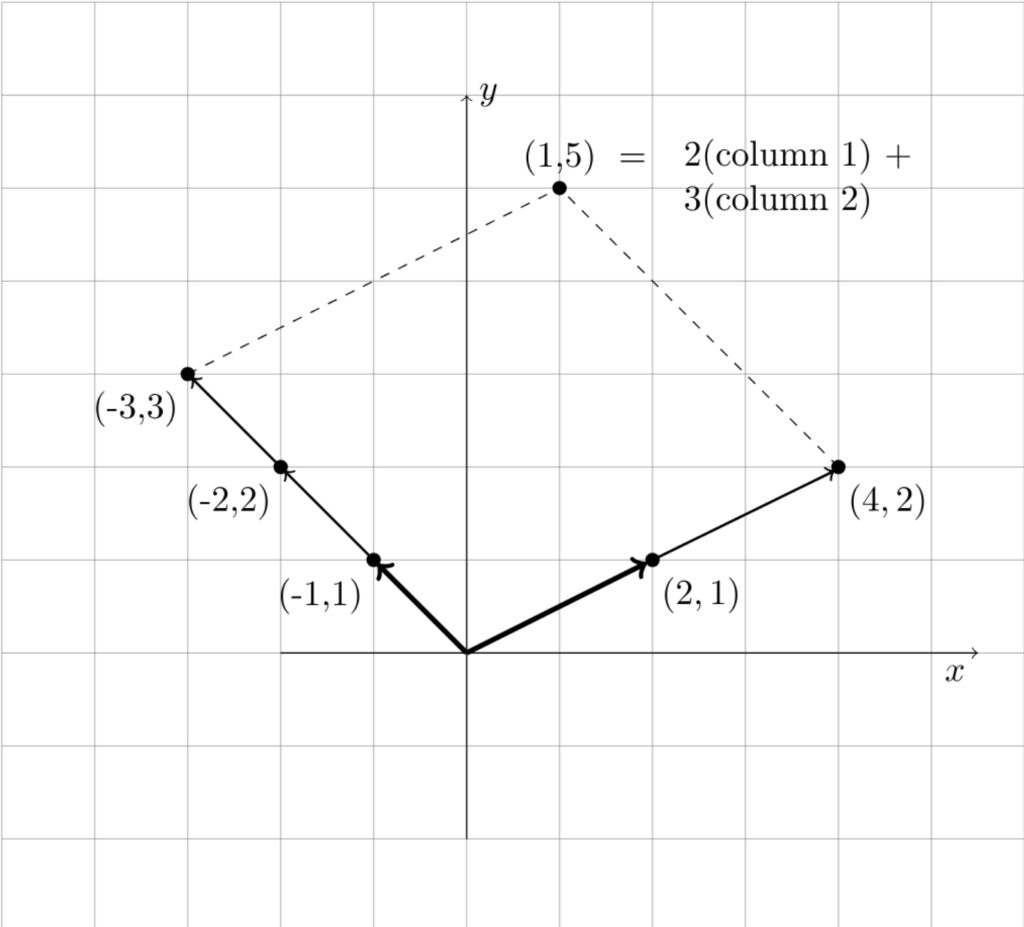
Note that  and
and  are column vectors. Thus, to solve this equation, we need to find values of and that produce a linear combination (or combinations) that yield the column vector
are column vectors. Thus, to solve this equation, we need to find values of and that produce a linear combination (or combinations) that yield the column vector  . As you might guess, those values are and . The following diagram illustrates that this is so.
. As you might guess, those values are and . The following diagram illustrates that this is so.
Solutions to linear equations
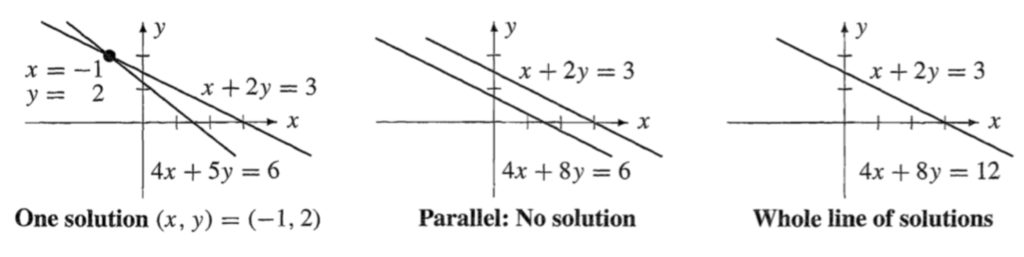
In the example above, there was one solution to the system of equations being considered. However, when attempting to solve a system of linear equations, there are 3 possible outcomes (seen best when considering the row view):
- One unique solution (line’s intersect)
- No solution (lines are parallel)
- An infinite number of solutions (lines overlap)
The following diagram taken from Strang’s texbook may make this clearer:
The situation is similar for systems of 3 linear equations. An example, again taken from Strang, will help to illustrate this:

The solution to this system of equations is  ,
,  and
and  .
.





All of the linear combinations that can be made from each of the equations in the example above yields a plane in 3D space. Like in the 2D case, there are 3 types of possible solutions:
- if the planes intersect at a point, then there is one unique solution to the system of equations
- if all 3 planes do not intersect, then there is no solution
- if the intersection of the 3 planes form a line, then there are an infinite number of solutions
When plotted using a free online graphing program,
https://technology.cpm.org/general/3dgraph/
the planes formed by the system of equations in our 3D example look like this:
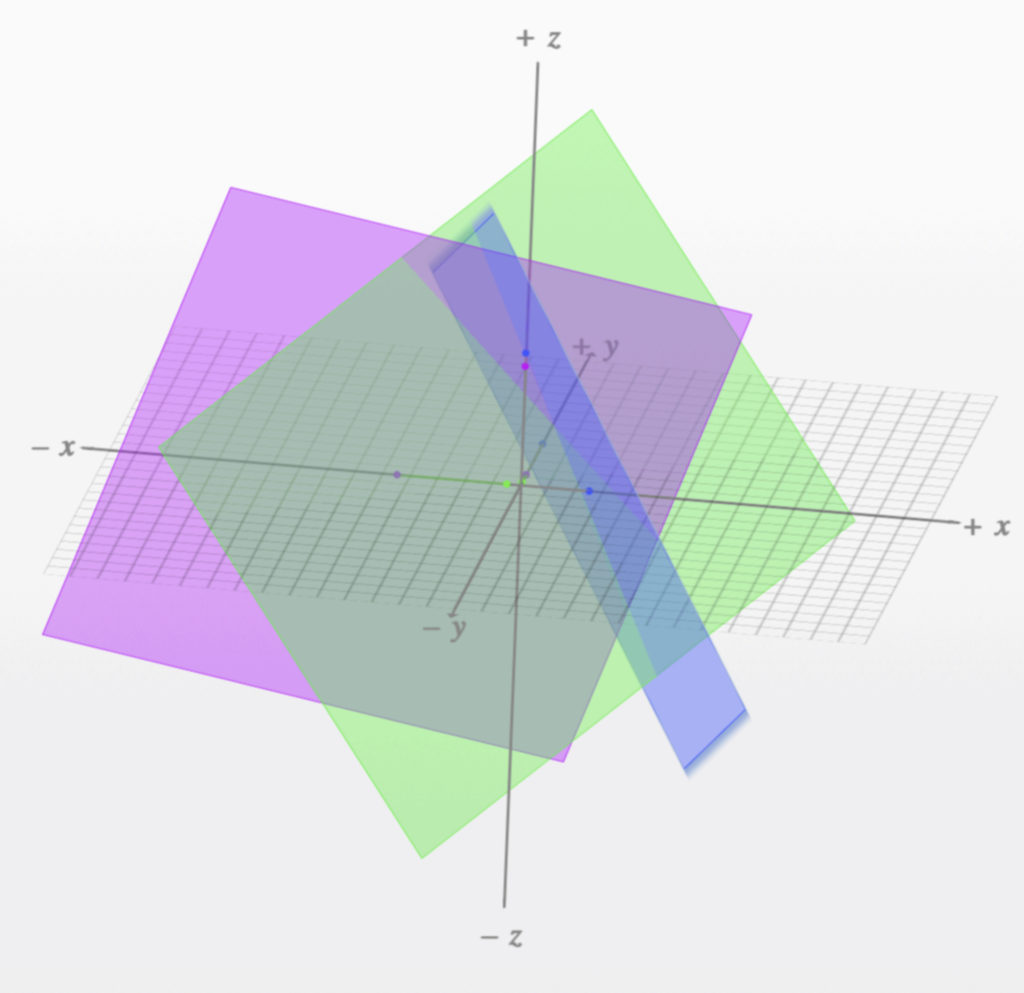
We can see from the diagram that the three planes intersect at a point. It’s difficult to precisely define this point on the diagram because of the difficulty in angling the axes in a way that optimally visualizes all three coordinates at once. However, if we could, the point that we would define would be  .
.
Matrices
A more efficient way to solve systems of linear equations is to make use of matrices. We’ll use the systems of equations we’ve considered above to illustrate how this works.
The general formula we’ll use is  where
where  is a matrix, is a vector and
is a matrix, is a vector and  is another vector. In the 2D example,
is another vector. In the 2D example,
- Take the coefficients on the left side of the system of equations and place them inside brackets, maintaining their row/column structure:
 . This is the matrix .
. This is the matrix . - Place the variables, and , into a column,
 . This is the vector
. This is the vector  .
. - Place the numbers on the right side of the equations into a column
 . This is the vector
. This is the vector  .
.
This gives us

To get back to our original system of linear equations, we need to apply matrix multiplication.
Mechanics of matrix multiplication
Matrix times a vector
2D matrix multiplication with a vector
Multiplying a matrix times a vector ( ) involves taking the dot product of the vector, with each of the columns of to create a new “1-column matrix” (better known as a vector). To illustrate this, let’s consider the simple 2D example first:
) involves taking the dot product of the vector, with each of the columns of to create a new “1-column matrix” (better known as a vector). To illustrate this, let’s consider the simple 2D example first:
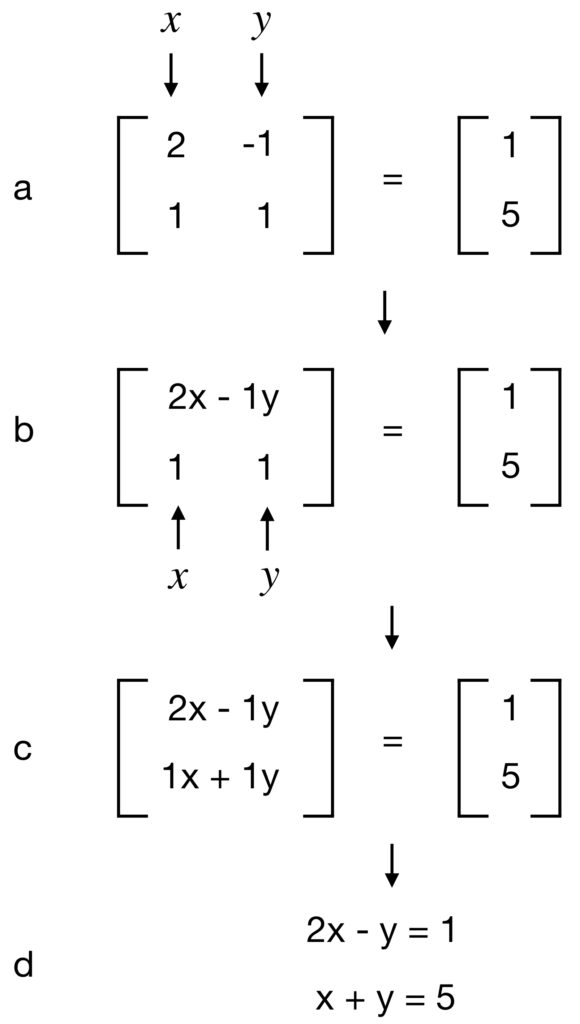
- a – Take the dot product of with the first row of the matrix by multiplying times
 and adding that to the product of times
and adding that to the product of times  . Then place that sum as a single entry in the top row of the matrix to yield the results seen in b.
. Then place that sum as a single entry in the top row of the matrix to yield the results seen in b. - b – Take the dot product of with the second row of the matrix by multiplying times and adding that to the product of times . Then place that sum as a single entry in the top row of the matrix to yield the results seen in c.
- c – Split the matrices into separate equations as in d.
- d – We have 2 equations in 2 rows, which is just what we started with.
- This shows that such a system of equations (i.e., the row description of these equations) is equivalent to our matrix equation.
Finally, we can take our matrix, and instead of taking the dot product of each row, we can multiply each column of our matrix by the appropriate coefficient of the vector (in this case, for our first column and for our second column). This gives us the column representation of our system of equations:
3D matrix multiplication with a vector
The 3-dimensional case is a bit more rigorous but follows the same principles. To illustrate this, we’ll examine the 3D system of equations we considered previously:

As we’ve seen, this system of equations can be represented as follows:
![\begin{equation*}\begin{bmatrix} \,\,\,\,\,2 & \,\,\,\,\,1 & 1 \\ \,\,\,\,\,4 & -6 & 0 \\ -2 & \,\,\,\,\,7 & 2 \end{bmatrix}\begin{bmatrix} u \\ v \\ w\end{bmatrix}=\begin{bmatrix} \,\,\,\,\,5 \\ -2 \\ \,\,\,\,\,9\end{bmatrix}\text{note that () can be used instead of [ ]}\end{equation*}](https://www.samartigliere.com/wp-content/ql-cache/quicklatex.com-cc76488558f4ac3c7be00406a6a7f4c4_l3.png "Rendered by QuickLaTeX.com")
We can move back to our original system of 3 equations by using matrix multiplication:
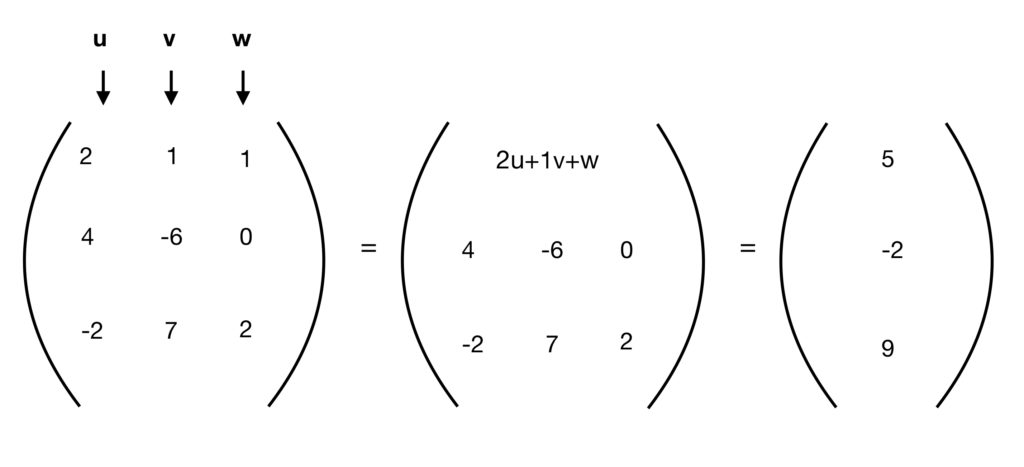
Step 1: Multiply the top row of the matrix by the column vector  (i.e., multiply times ,
(i.e., multiply times ,  times and
times and  times 1). Add these products together and make this sum the first row/first column in a new matrix.
times 1). Add these products together and make this sum the first row/first column in a new matrix.
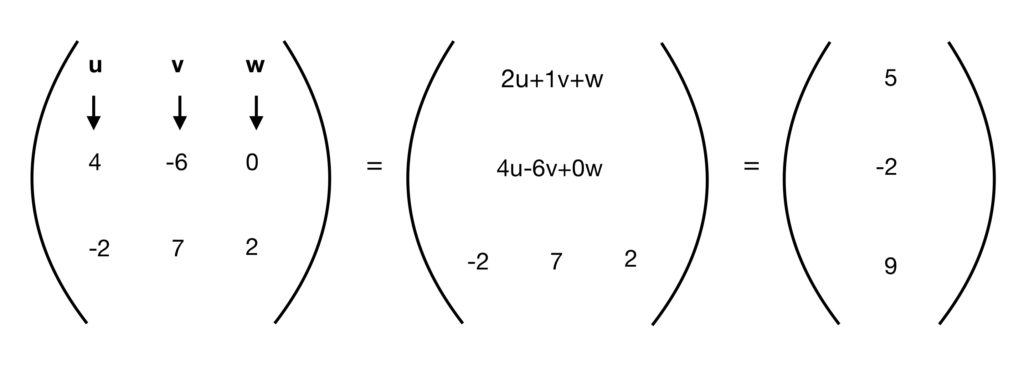
Step 2: Multiply the second row of the matrix by the column vector (i.e., multiply times  , times
, times  and times 0). Add these products together and make this sum the second row/first column in the new matrix.
and times 0). Add these products together and make this sum the second row/first column in the new matrix.
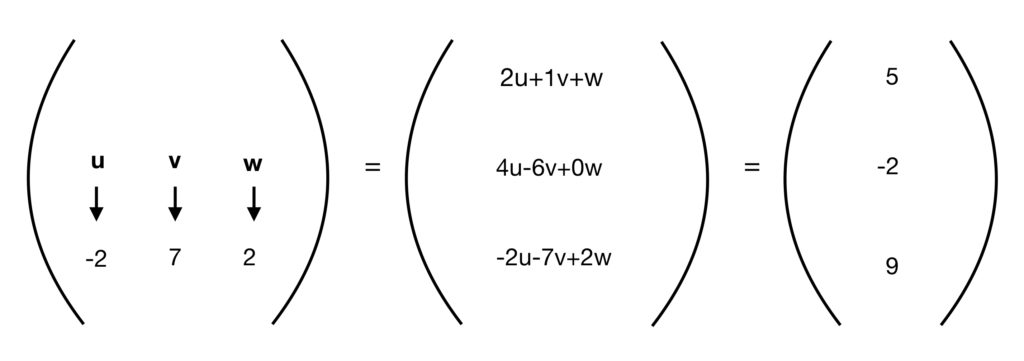
Step 3: Multiply the top third row of the matrix by the column vector (i.e., multiply times , times  and times 2). Add these products together and make this sum the third row/first column in a new matrix.
and times 2). Add these products together and make this sum the third row/first column in a new matrix.
With this, we’re back to our original system of equations, represented in row form. Of course, if we multiply each column by the appropriate vector coefficient (i.e., for the first column, for the first column and for the first column, we get the also-equivalent column representation:

Matrix times matrix
We can also multiply 2 matrices, and  together to get a new matrix,
together to get a new matrix,  . To do this, the dot product of each column in the matrix on the right of a matrix-matrix multiplication expression is taken with the rows of the matrix on the left, exactly like in matrix-vector multiplication. This creates a column in a new matrix with a relative position that is the same as the column that was used to create it. It looks like this:
. To do this, the dot product of each column in the matrix on the right of a matrix-matrix multiplication expression is taken with the rows of the matrix on the left, exactly like in matrix-vector multiplication. This creates a column in a new matrix with a relative position that is the same as the column that was used to create it. It looks like this:


An example with numbers is as follows:

The identity matrix, I
The identity matrix is a matrix with 1’s on its diagonal elements and 0’s everywhere else. For example
Examples

Properties
1. Any matrix multiplied by the identity matrix gives back the original matrix

For example

Geometric interpretation of matrix multiplication
As suggested in our previous discussion related to systems of linear equations, an evaluation of the geometry of matrix multiplication may further our understanding of the process. Specifically, it may be helpful to think of the matrix as a machine that performs an operation on a vector to yield a new vector. The operation it performs is a linear transformation. Geometrically, what this means is that the matrix establishes the coordinate system in which the vector should be represented.
It’s useful to realize that the matrix equation  is equivalent to the equation
is equivalent to the equation  where is the identity matrix. This viewpoint is because 1) the identity matrix times any matrix gives back the original matrix and 2) a vector can be thought of as a one dimensional matrix. It turns out that the coordinate system that creates is just the Cartesian coordinate system with which we’re all familiar where 1) the basis vectors used to build up other vectors are unit vectors perpendicular to each other 2) the axes of the coordinate system are perpendicular to each other and 3) the spacing between units on those axes is 1 unit in length everywhere.
where is the identity matrix. This viewpoint is because 1) the identity matrix times any matrix gives back the original matrix and 2) a vector can be thought of as a one dimensional matrix. It turns out that the coordinate system that creates is just the Cartesian coordinate system with which we’re all familiar where 1) the basis vectors used to build up other vectors are unit vectors perpendicular to each other 2) the axes of the coordinate system are perpendicular to each other and 3) the spacing between units on those axes is 1 unit in length everywhere.
What the linear transformation performed by does is change the length and direction of basis vectors from that created by while 1) keeping the origin of the coordinate system at the same point as the Cartesian coordinate system and 2) keeping grid lines associated with the coordinate system straight, parallel and evenly spaced.
What solving a matrix equation like ultimately involves, then, is finding the coordinates of , in the coordinate system created by , that make the end of the vector so created land on the same point in space as that specified by the vector in the coordinate system created by . In essence, the vectors on both sides of the matrix equation point to the same point in space. It’s just that we are “looking at space” differently in the two coordinate systems. This is what makes the coefficients of and different.
2D example
I realize that these ideas, as expressed in words in the previous paragraphs, seem convoluted. Therefore, let me try to make things clearer with an example. Let’s consider the 2D system of equations we’ve been working with already:
The matrix equation that corresponds to this system of equations is:
![\[\begin{bmatrix} 2 & -1 \\ 1 & \,\,\,\,\,1 \end{bmatrix}\begin{bmatrix} x \\ y \end{bmatrix} = \begin{bmatrix} 1 \\ 5 \end{bmatrix}\]](https://www.samartigliere.com/wp-content/ql-cache/quicklatex.com-9d27b5ea908962c64ad47691ffe97976_l3.png "Rendered by QuickLaTeX.com")
This is equivalent to:
![\[\begin{bmatrix} 2 & -1 \\ 1 &\,\,\,\,\, 1 \end{bmatrix}\begin{bmatrix} x \\ y \end{bmatrix} = \begin{bmatrix} 1 & 0\\ 0 & 1 \end{bmatrix}\begin{bmatrix} 1 \\ 5 \end{bmatrix}\]](https://www.samartigliere.com/wp-content/ql-cache/quicklatex.com-5b73653ac95f9a8a56f697ce261bdf86_l3.png "Rendered by QuickLaTeX.com")
The column picture of this equation is:
This is equivalent to:
![\[ x\begin{bmatrix} 2\\1 \end{bmatrix} + y\begin{bmatrix} -1\\\,\,\,\,\,1 \end{bmatrix} = 1\begin{bmatrix} 1\\0 \end{bmatrix} + 5\begin{bmatrix} 0\\1 \end{bmatrix}\]](https://www.samartigliere.com/wp-content/ql-cache/quicklatex.com-f5591397a25ccbd361ea65a95740f9ec_l3.png "Rendered by QuickLaTeX.com")
To solve this equation, in this simple example, a picture will help:
In the diagram:
- The thick black lines represent the x (horizontal) and y (vertical) axes of the Cartesian coordinate system created by
- The grid of light blue lines represents the coordinate grid of that Cartesian coordinate system
- The thick blue lines represent the x and y axes of the coordinates system specified by matrix
- The darker blue lines that are parallel to the thick blue axes represent the coordinate grid associated with matrix
If we let  represent the unit vector in the x-direction of the Cartesian coordinate system and
represent the unit vector in the x-direction of the Cartesian coordinate system and  represent the unit vector in the y-direction. Then,
represent the unit vector in the y-direction. Then,
- Matrix transforms
 to
to 
- Matrix transforms
 to
to 
- Note that the columns of our matrix, , are the new basis vectors that our matrix creates: the left-hand column is the transformed version of (which we’re calling
 ; the right-hand column is the transformed version of (which we’re calling
; the right-hand column is the transformed version of (which we’re calling  )
)
The green lines represent the vector addition in the Cartesian coordinate system:
- +1 unit in the direction of

- +5 units in the direction of
The red lines represent the vector addition needed to get to the same point in space in the coordinate system specified by . That vector addition is:
 units in the direction of
units in the direction of  units in the direction of
units in the direction of
The above discussion is based on the following YouTube video from 3Blue1Brown: https://www.youtube.com/watch?v=kYB8IZa5AuE
I encourage readers to watch the entire series because 1) it explains the “why” behind a multitude of concepts, something that is missing in many discussions on linear algebra and 2) it has some great animations that illustrate these concepts more clearly than words and equations ever could.
3D and higher dimensional linear transformations
As you might guess, we can apply this linear transformation perspective to 3D equations in a manner similar to the way it was applied to the 2D situation. The 3D equation system we’ve examined previously will serve as an illustration. Recall that the column view of that system was expressed as follows:
We can use this equation to make a matrix equation of the form :

The basis vectors that we’ll use to produce the Cartesian coordinate system and define the 3D vector,  are
are  ,
,  , and
, and  . The matrix, transforms these basis vectors to new basis vectors,
. The matrix, transforms these basis vectors to new basis vectors,  ,
,  , and
, and  . The number of units-, , and -that we move along our basis vectors,
. The number of units-, , and -that we move along our basis vectors,  ,
,  and
and  , respectively, is the solution to our equation system. This is a bit difficult to visualize on the diagrams that I could draw, but the animations from this additional video from 3Blue1Brown illustrate this approach nicely: https://www.youtube.com/watch?v=rHLEWRxRGiM
, respectively, is the solution to our equation system. This is a bit difficult to visualize on the diagrams that I could draw, but the animations from this additional video from 3Blue1Brown illustrate this approach nicely: https://www.youtube.com/watch?v=rHLEWRxRGiM
Part of the beauty of linear algebra is that we can generalize the above principles to as many dimensions as we want-an infinite number of dimensions, in fact-as in the case of a continuous function.
If you were like me when I started learning about this subject, you might be wondering what a multi-dimensional vector is and why would we want one. To understand this, we need to recognize that there are entities that can be represented by vectors other than spatial position.
A common thing that could be represented on our axes might be probabilities. For example, in quantum mechanics, outcomes for an experiment are not a certainty, but instead, can only be expressed as a series of probability amplitudes, one for each outcome. Suppose there are 5 possible outcomes for the experiment. We can define a 5-dimensional vector with the probability amplitude (which can be squared to get the probability) for each of outcome represented by one of the 5 axes.
Momentum in quantum mechanics is an even more extreme example. At any given moment, the momentum of a particle in a given direction varies over an infinite number of possibilities, each possible momentum value having a given probability of occurring. This is a continuous function. The number of axes needed to represent this situation would be infinite.
However, in each case, the vectors employed obey linearity and form a vector space. Such instances may be difficult (or impossible) to describe visually but all of the methods we’ve been talking about can be applied.
Matrix multiplication as a linear transformation
We can also think of matrix multiplication as a composition of linear transformations. Again, a great visual presentation of this viewpoint is given by the 3Blue1Brown series on linear algebra: https://www.youtube.com/watch?v=XkY2DOUCWMU
Here is the essence of the argument presented in that video:
- The action of a matrix can be thought of as creation of a new coordinate system that makes a vector on which it acts change its length and/or direction
- Therefore, when, for example, we multiply 2 matrices together to get a new matrix (e.g.
 ), the matrix on the right, , transforms the Cartesian coordinate system into a new coordinate system. Then subsequently, the matrix on the left, , transforms that new coordinate system into an even newer coordinate system. And that new coordinate system can be created directly by a new matrix, , a new matrix that is the result of multiplying matrix with matrix
), the matrix on the right, , transforms the Cartesian coordinate system into a new coordinate system. Then subsequently, the matrix on the left, , transforms that new coordinate system into an even newer coordinate system. And that new coordinate system can be created directly by a new matrix, , a new matrix that is the result of multiplying matrix with matrix
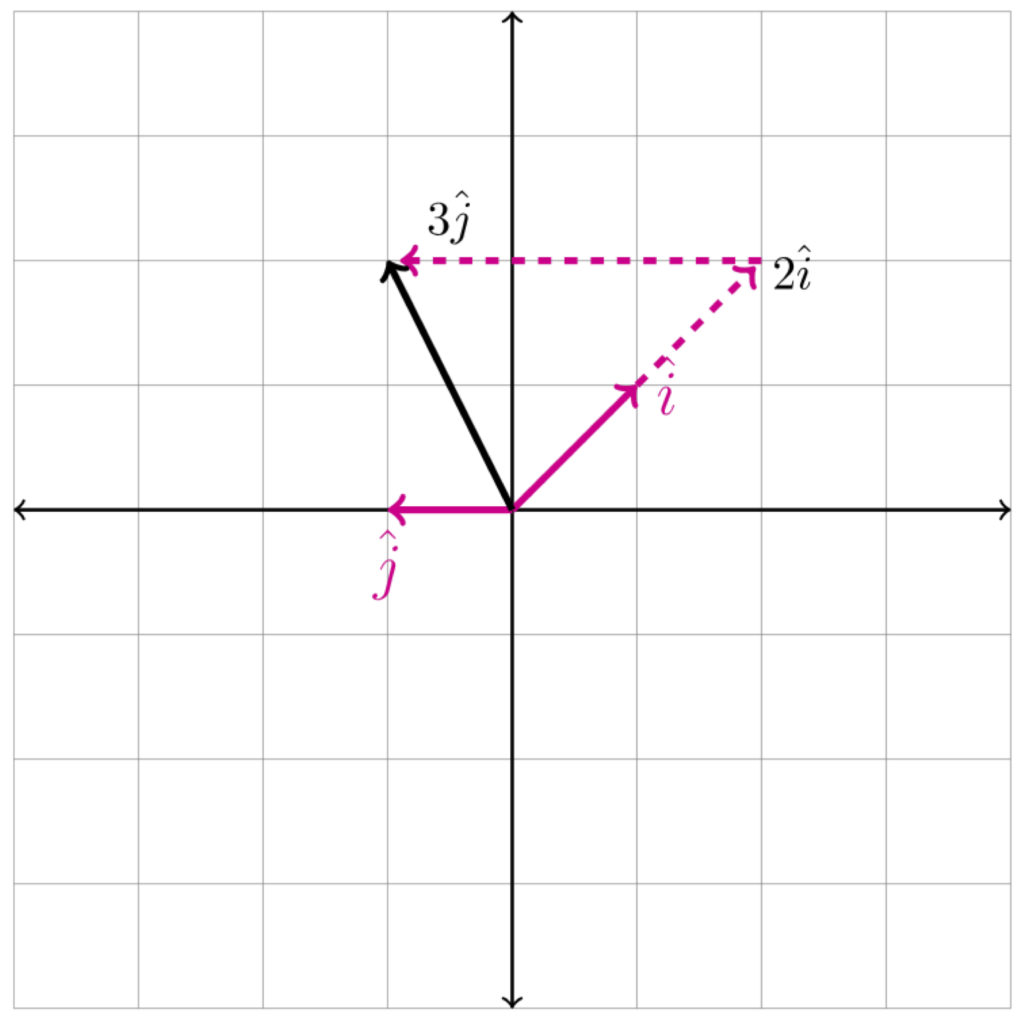
The example given in the video begins with a matrix, , that rotates a vector in space counterclockwise 90° (called a rotation matrix):
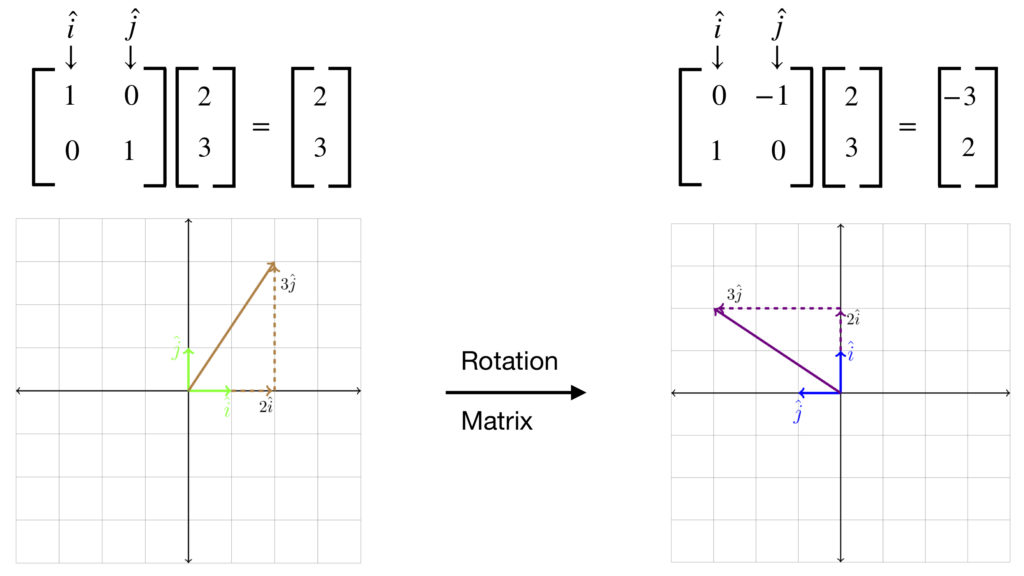
As in our previous discussion about linear transformations, the essence of what’s happening in this operation is that the rotation matrix, , changes the basis vectors from those of the Cartesian coordinate system specified by the identity matrix to a coordinate system specified by matrix :  to
to  and to . Note that the left-hand columns of each matrix specify the basis vector and the right-hand columns specify . The vector upon which the identity matrix, , and “operate” is
and to . Note that the left-hand columns of each matrix specify the basis vector and the right-hand columns specify . The vector upon which the identity matrix, , and “operate” is  . When operates on this vector, it returns the same result. However, when acts on it, the result is
. When operates on this vector, it returns the same result. However, when acts on it, the result is  . This problem can be looked at from two viewpoints: the row viewpoint and the column viewpoint. The column viewpoint is illustrated in the diagram:
. This problem can be looked at from two viewpoints: the row viewpoint and the column viewpoint. The column viewpoint is illustrated in the diagram:
![\[ 2\hat{i} + 3\hat{j} = 2\begin{bmatrix}0\\1\end{bmatrix}+ 3\begin{bmatrix}-1\\\,\,\,\,\,0\end{bmatrix}= \begin{bmatrix}-3\\\,\,\,\,\,2\end{bmatrix}\]](https://www.samartigliere.com/wp-content/ql-cache/quicklatex.com-5fc9c51d420adc3b08a74a1a686d140f_l3.png "Rendered by QuickLaTeX.com")
The second matrix considered in the video, which we’ll call , works by “stretching” vectors (i.e., it creates a so-called shear):
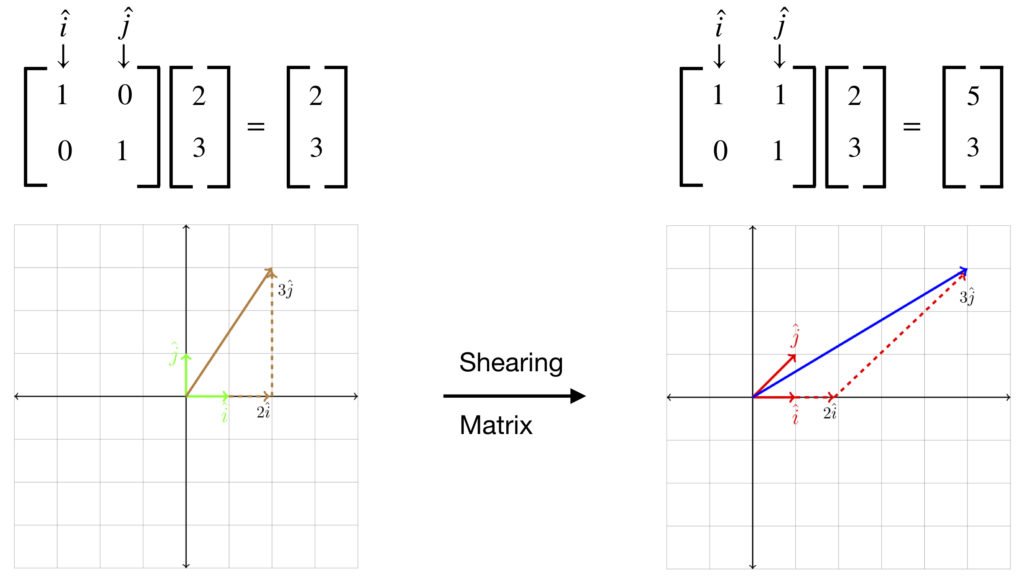
Again, the column viewpoint is illustrated in the diagram:
![\[ 2\hat{i} + 3\hat{j} = 2\begin{bmatrix}1\\0\end{bmatrix}+ 3\begin{bmatrix}1\\1\end{bmatrix}= \begin{bmatrix}5\\3\end{bmatrix}\]](https://www.samartigliere.com/wp-content/ql-cache/quicklatex.com-30b5c43efbe6c9f1e6226898644b62f7_l3.png "Rendered by QuickLaTeX.com")
But what is the effect of first applying the rotation matrix, , on the vector , then applying the shearing matrix, (i.e.,  where is some unknown vector result, and in our example,
where is some unknown vector result, and in our example,  )? There are two ways to look at this.
)? There are two ways to look at this.
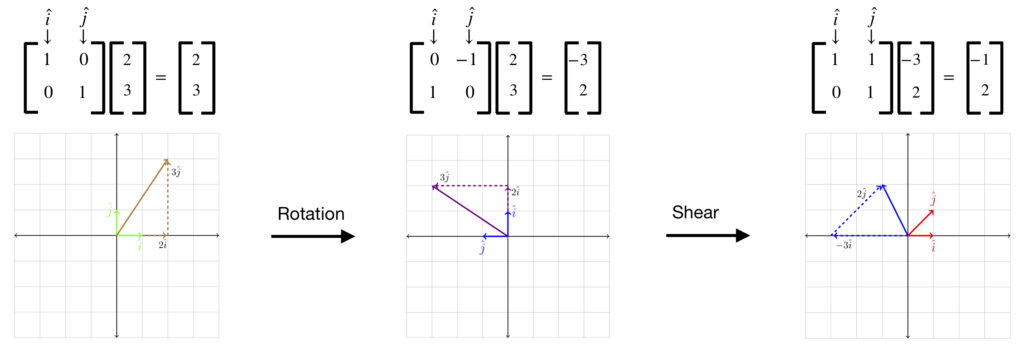
The first viewpoint is shown above. In the initial step of this method, the rotation matrix acts on to yield a new vector, . The shearing matrix is then applied to to give our final result,  . (We called vector in the equation
. (We called vector in the equation  above).
above).
The second viewpoint from which we can examine this problem is to multiply matrices and to make a new (which we’ll call a composite matrix) then allow this composite matrix to act on to produce . This process is worth examining in detail as this is the major point of this section.
Recall that each column of a matrix can be thought of as representing a basis vector. By multiplying 2 matrices together (say time , in that order), what’s actually happening is that is transforming (linearly) each basis vector specified in each column of into a new basis vector, and these new basis vectors are used to form the columns of a new matrix.
The first step in this process is shown below:
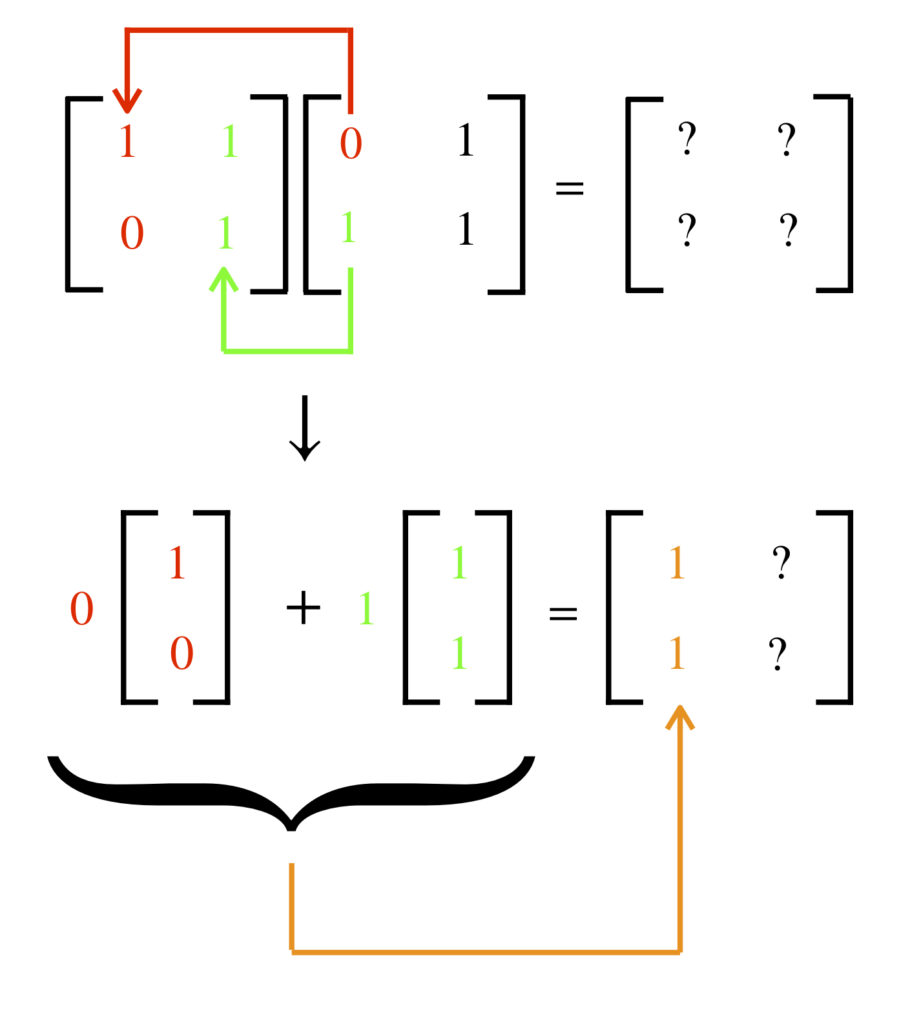
The second step occurs in a similar manner:
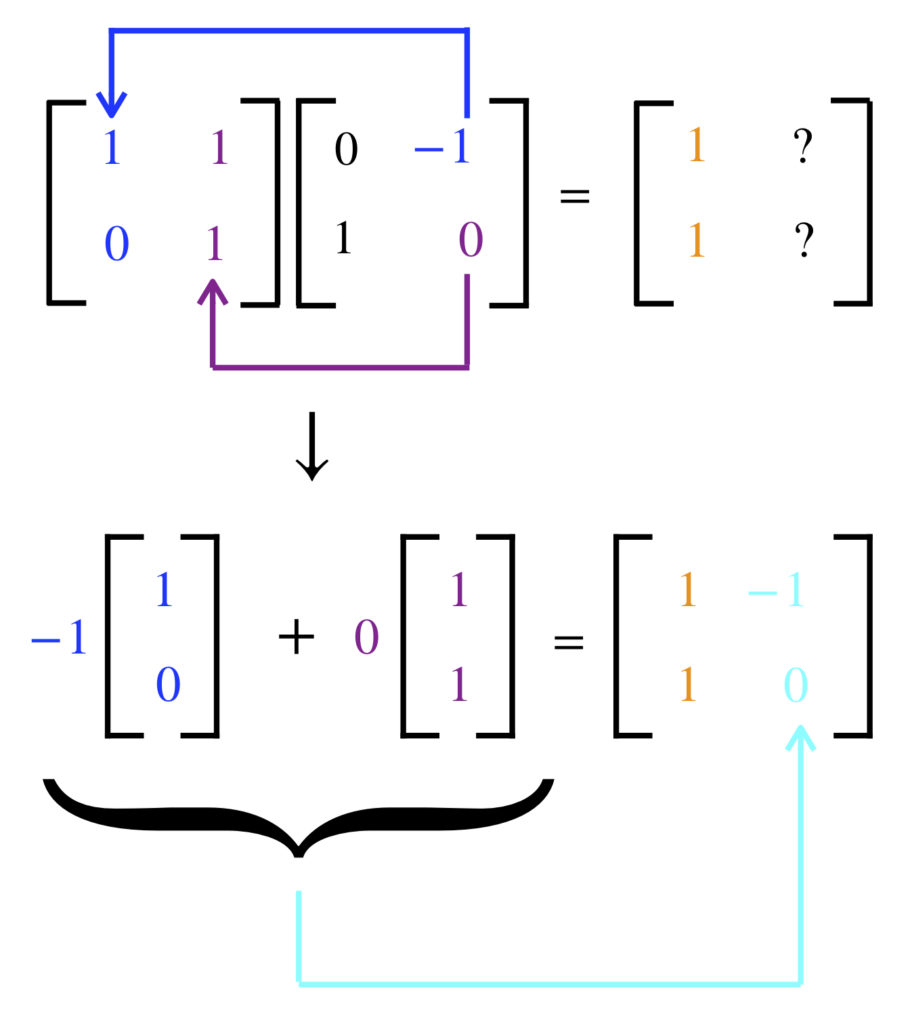
The end result is:
![\[ \begin{bmatrix} 1&0\\1&1 \end{bmatrix}\begin{bmatrix} \,\,\,\,\,0&1\\-1&0 \end{bmatrix}= \begin{bmatrix} \,\,\,\,\,1&1\\-1&0 \end{bmatrix}\]](https://www.samartigliere.com/wp-content/ql-cache/quicklatex.com-f103be0ee79951896d0b3de13d48717c_l3.png "Rendered by QuickLaTeX.com")
Now multiply the composite matrix on the right, , with  . Just as when we sequentially applied on
. Just as when we sequentially applied on  , then applied on this result, we get
, then applied on this result, we get  :
:
Algebraically, 
The punchline of this discussion comes from comparing the result of multiplying matrices by the method resulting from the geometric argument described above with the rote mechanical multiplication algorithm described earlier. Here is the result obtained by the geometric argument:
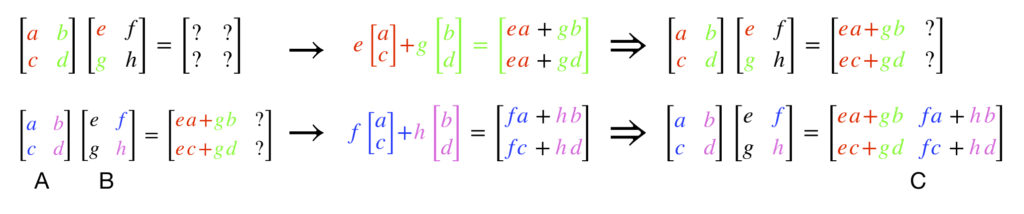 basis vector of is transformed by into a new basis vector which becomes the basis vector of a new matrix. In the second step (shown in the lower row, the basis vector of is transformed by into a new basis vector which becomes the basis vector of the new matrix.
basis vector of is transformed by into a new basis vector which becomes the basis vector of a new matrix. In the second step (shown in the lower row, the basis vector of is transformed by into a new basis vector which becomes the basis vector of the new matrix.Compare this with the rote technique described in the section entitled Matrix times matrix.
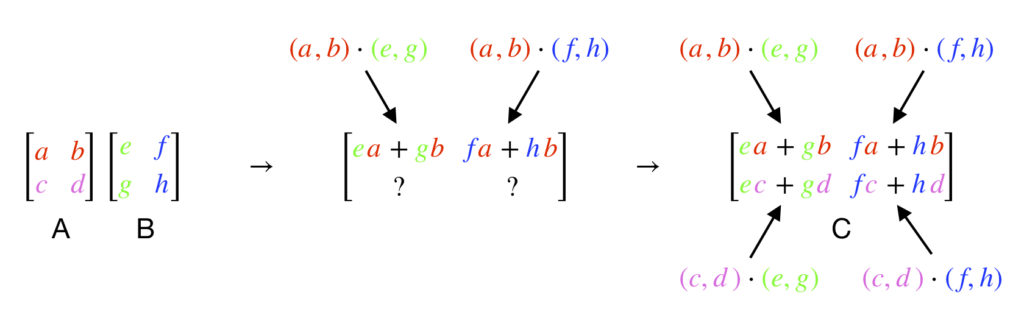 and the top row of . The result becomes the
and the top row of . The result becomes the  entry of a new matrix. Next, the dot product is taken between the the left-hand column of and the bottom row of . The result becomes the
entry of a new matrix. Next, the dot product is taken between the the left-hand column of and the bottom row of . The result becomes the  entry of the new matrix. The process is then repeated by dotting the right-hand column of with the top and bottom rows of to yield the
entry of the new matrix. The process is then repeated by dotting the right-hand column of with the top and bottom rows of to yield the  and
and  entries of , respectively .
entries of , respectively .Note that the result from both the method derived from the geometric argument and the rote method produce the same result, matrix . Few would debate that the rote method is a faster/more efficient way to do matrix multiplication. However, it is worthwhile to see the geometric interpretation of matrix multiplication-at least once-to gain some intuition as to why the rote method works.
Commutation relationship between matrices
Let’s re-examine the 2-dimension example we’ve already been working with and see what happens if we change the order of matrix multiplication. Let be the rotation matrix  and the shearing matrix
and the shearing matrix  . The question we want to ask is, “Does
. The question we want to ask is, “Does  ?” We already know that
?” We already know that  . We next need to calculate
. We next need to calculate  . We’ll do it the easy way-by the rote method:
. We’ll do it the easy way-by the rote method:
![\[BA=\begin{bmatrix}1&0\\1&1\end{bmatrix}\begin{bmatrix}0&-1\\1&\,\,\,\,\,0\end{bmatrix}=\begin{bmatrix}0&-1\\1&\,\,\,\,\,1\end{bmatrix} \]](https://www.samartigliere.com/wp-content/ql-cache/quicklatex.com-6f1c396a0541d39abd6ea17c1fb80baa_l3.png "Rendered by QuickLaTeX.com")
 which means that
which means that  . There’s a term for the quantity
. There’s a term for the quantity  . It’s called the commutator of and . If the commutator,
. It’s called the commutator of and . If the commutator,  (i.e., ) it is said that matrices and commute. If
(i.e., ) it is said that matrices and commute. If  (i.e., ) as in the example we just examined, it is said that and do not commute.
(i.e., ) as in the example we just examined, it is said that and do not commute.
Most of time, matrices do not commute, but at times, they do. For example, take the matrix  . To find a matrix (or matrices), , that commute(s) with , we do the following:
. To find a matrix (or matrices), , that commute(s) with , we do the following:
Let . Let  . If the two matrices commute, then
. If the two matrices commute, then
![\[\begin{bmatrix}a&b\\c&d\end{bmatrix}\begin{bmatrix}2&3\\1&4\end{bmatrix}=\begin{bmatrix}2&3\\1&4\end{bmatrix}\begin{bmatrix}a&b\\c&d\end{bmatrix} \]](https://www.samartigliere.com/wp-content/ql-cache/quicklatex.com-a5e95a80d5b67e09186b96d8de756f3c_l3.png "Rendered by QuickLaTeX.com")
![\[ \begin{bmatrix}a&b\\c&d\end{bmatrix}\begin{bmatrix}2&3\\1&4\end{bmatrix}=\begin{bmatrix}2a+b & 3a+4b\\2c+d & 3c+4b \end{bmatrix}\]](https://www.samartigliere.com/wp-content/ql-cache/quicklatex.com-acd6eab81db0bf9ca35d7a4352a0103e_l3.png "Rendered by QuickLaTeX.com")
And
![\[\begin{bmatrix}2&3\\1&4\end{bmatrix}\begin{bmatrix}a&b\\c&d\end{bmatrix}=\begin{bmatrix}2a+3c & 2b+3d\\a+4c & b+4d \end{bmatrix} \]](https://www.samartigliere.com/wp-content/ql-cache/quicklatex.com-671d693b1e488483ab819b729ebacfae_l3.png "Rendered by QuickLaTeX.com")
Because , each entry of  should equal its corresponding entry from . This gives us the following 4 equations in 4 unknowns:
should equal its corresponding entry from . This gives us the following 4 equations in 4 unknowns:

The top and bottom equations are the same. The second and third equations are also the same. Therefore, we’re left with the following 2 equations:

So, a matrix that will commute with  takes this form:
takes this form:

That means that we can choose any numbers for values of  and . As long as the above relationships are maintained, matrix will commute with matrix .
and . As long as the above relationships are maintained, matrix will commute with matrix .
For example, let  and
and  . Then the matrix, should commute with the following matrix (we’ll call it ):
. Then the matrix, should commute with the following matrix (we’ll call it ):

Let’s check it out:

and

So it works!
Solving matrix equations 1
The main method of solving matrix equations such as or their equivalent, systems of linear equations, is Gaussian elimination. We’ve touched on this briefly when we’ve had to solve such systems. However, we will take a closer look at his method here.
The basic idea behind is to take an equation like this:
 and turn it into an equation like this:
and turn it into an equation like this:

where the  are some number (that can include 0) and the
are some number (that can include 0) and the  are numbers other than 0.
are numbers other than 0.
We’ll call the matrix with all . We’ll call the matrix a combination of , and 
 because it is what’s called an upper triangular matrix. That means that 1) the upper right-hand portion of the matrix, which forms a triangle, consists of non-zero numbers along its diagonal and other numbers (zero or non-zero) above and to the right of the diagonal while 2) the lower left-hand portion of is all 0’s. The dot product of \vec x with the bottom row of gives
because it is what’s called an upper triangular matrix. That means that 1) the upper right-hand portion of the matrix, which forms a triangle, consists of non-zero numbers along its diagonal and other numbers (zero or non-zero) above and to the right of the diagonal while 2) the lower left-hand portion of is all 0’s. The dot product of \vec x with the bottom row of gives  (a number) time
(a number) time  (a variable), and that is equal to another number,
(a variable), and that is equal to another number,  , the bottom entry in a new vector,
, the bottom entry in a new vector,  . This equation allows us to solve for . The value of is then back-substituted into the equation above it to solve for
. This equation allows us to solve for . The value of is then back-substituted into the equation above it to solve for  ; the values of and are substituted into the second from top equation to solve for
; the values of and are substituted into the second from top equation to solve for  ; and finally, the values of , and are back-substituted into the top equation to get the value of
; and finally, the values of , and are back-substituted into the top equation to get the value of  . That solves the system of equations.
. That solves the system of equations.
This algorithm is illustrated by the following example:

Multiply the top equation by 2 and subtract it from equation 2. We get:

Subtract the top equation from the bottom equation. That gives:

Multiply the middle equation by 2 and subtract it from it from bottom equation. We’re left with:

So  . Back-substitute into the middle equation:
. Back-substitute into the middle equation:
![\[y+z=1 \Rightarrow y+0=1 \Rightarrow y=1\]](https://www.samartigliere.com/wp-content/ql-cache/quicklatex.com-6f4d2683760abc6fc120a69316b6ec7f_l3.png "Rendered by QuickLaTeX.com")
Back-substitute into the top equation. That leaves:
![\[ 2x-3y=3 \Rightarrow 2x-3\cdot 1 =3 \Rightarrow 2x=6 \Rightarrow x=3\]](https://www.samartigliere.com/wp-content/ql-cache/quicklatex.com-13a2c46904af3b1ca67383ded5099e0f_l3.png "Rendered by QuickLaTeX.com")
The same system of equations represented in matrix equation form is:
![\[\begin{bmatrix} 2&-3&\,\,\,0\\4&-5&\,\,\,1\\2&-1&-3 \end{bmatrix}\begin{bmatrix} x\\y\\z \end{bmatrix}=\begin{bmatrix} 3\\7\\5 \end{bmatrix}\]](https://www.samartigliere.com/wp-content/ql-cache/quicklatex.com-b282afbb1bf993198939738d5cd15c10_l3.png "Rendered by QuickLaTeX.com")
What we’re manipulating when we do Gaussian elimination is numbers-specifically the coefficients of the variables, , and  and the numbers on the right-hand side of the equal sign. Therefore, we can create a short-hand for doing Gaussian elimination that will make the process more efficient:
and the numbers on the right-hand side of the equal sign. Therefore, we can create a short-hand for doing Gaussian elimination that will make the process more efficient:

The numbers to the left of the vertical line are matrix elements. The numbers to the right of the vertical line are “the answers” to the 3 equations, if you’re taking the row viewpoint, or the coefficients of the resultant vector, if you’re taking the column viewpoint. We could equally just place all of these numbers into one matrix, called an augmented matrix, and proceed as we did above, as long as we remember that the number to the far right is equivalent to the number to the right of the vertical line in our other shorthand (not too hard to do):
![\[ \begin{bmatrix} 2 &-3&\,\,\,\,\,0&3\\4 &-5& \,\,\,\,\,1&7\\2 &-1& -3&5 \end{bmatrix} \]](https://www.samartigliere.com/wp-content/ql-cache/quicklatex.com-b0867c5d8527648f736d51e55194df0d_l3.png "Rendered by QuickLaTeX.com")
Here are a few key facts about the solutions we get from the process of Gaussian elimination:
- If Gaussian elimination yields a matrix like that pictured above-an upper triangular matrix with numbers on the diagonal elements (called pivots)-then the system of equations will have one specific solution.
- If Gaussian elimination winds up with a row that says 0 equals some number, then there will be no solution.
- If Gaussian elimination ends up with a row that says 0 = 0, then the system of equations will have an infinite number of solutions.
The last two bullet points are probably worth some additional explanation. Remember, the matrix representation of a system of equations represents just that-equations. Say we have a system of equations with three variables. Say we wind up with a row of zeros in our last row. That means

We could put in any number in for any of the variables. Therefore, there are an infinite number of solutions.
Likewise, if we have something like this:

No matter what numbers we put in for any of the variables, that equation will never be true. Therefore, there is no solution to this system of equations.
All of the matrices we have considered so far are square matrices (i.e., # of rows = # of columns). Note that if such a matrix has just one solution, it’s called nonsingular. If it has no solution or an infinite number of solutions, it’s called singular. Note also that the first nonzero entry in a given row is called a pivot. From the above discussion, it is evident that if, after elimination, there are non-zero numbers in every diagonal position (i.e, all of the diagonal entries are pivots), then the matrix will be nonsingular. If there is a row of zeros in the matrix, then there necessarily will be a 0 on a diagonal entry. In such a case, then, that matrix has to be singular (since we’ll wind up with a row that gives us 0 = 0 or 0 = some nonzero number, which mean an infinite number of solutions or zero solutions, respectively). We’ll have more to say about nonsingular and singular matrices later.
The above example makes use of multiplying and subtracting equations to perform elimination. We could also add equations. Strang’s textbook follows the convention of subtracting equations rather than adding, noting that multiplying by -1 then subtracting has the same effect as adding. In some cases, adding equations may be preferable, especially when using augmented matrices (discussed below) to solve equations. For continuity, we’ll generally subtract one equation from another, noting when we use addition instead.
The other technique that can sometimes be useful is to exchange rows. The following example, taken from Strang’s textbook, illustrates this latter technique:

In augmented matrix form, this becomes:
![\[\begin{bmatrix} 1&2&2&1\\4&8&9&3\\0&3&2&1 \end{bmatrix}\]](https://www.samartigliere.com/wp-content/ql-cache/quicklatex.com-a842b39aaa592d55126db4cbe953734c_l3.png "Rendered by QuickLaTeX.com")
Multiply the top equation by 4 and subtract it from the second equation to get a new second equation. That gives us:
![\[\begin{bmatrix} 1&2&2&\,\,\,\,\,1\\0&0&1&-1\\0&3&2&\,\,\,\,\,1 \end{bmatrix}\]](https://www.samartigliere.com/wp-content/ql-cache/quicklatex.com-6ec22ef8100e843887c7d2dbccec056e_l3.png "Rendered by QuickLaTeX.com")
At this point, rather than performing multiplication/subtraction step between the top and bottom equations then another multiplication/subtraction step between the middle and bottom rows, it’s easier to just exchange the middle and bottom rows. That yields:
![\[\begin{bmatrix} 1&2&2&\,\,\,\,\,1\\0&3&2&\,\,\,\,\,1\\ 0&0&1&-1\end{bmatrix}\]](https://www.samartigliere.com/wp-content/ql-cache/quicklatex.com-cebca3620814be4f5ee12aa281fae889_l3.png "Rendered by QuickLaTeX.com")
Now take the coefficients and numbers specified by the matrix above and convert them back into equations:

So

We can also create matrices that bring about row multiplication/subtraction steps and row exchanges. The basic idea is to modify the identity matrix to produce these results. Recall that the identity matrix, when multiplied by any other matrix, returns the original matrix. Therefore, we have but to change one other entry in to produce a multiplication/subtraction step or row exchange.
Following the lead of Strang’s text, we’ll call a matrix that produces a multiplication/subtraction (or addition) step an elimination matrix,  , and a matrix that produces a row exchange a permutation matrix,
, and a matrix that produces a row exchange a permutation matrix,  . Suppose we want to apply a multiplication/subtraction step (let’s call such a step an elimination step) by applying on some matrix (call it ). We want to eliminate a term from an equation represented by some row in (call it row b) by subtracting the analogous term from another row in , (call it row a). To do this, we multiply the coefficient for the term in row a by a multiplication factor,
. Suppose we want to apply a multiplication/subtraction step (let’s call such a step an elimination step) by applying on some matrix (call it ). We want to eliminate a term from an equation represented by some row in (call it row b) by subtracting the analogous term from another row in , (call it row a). To do this, we multiply the coefficient for the term in row a by a multiplication factor,  , such that, when we subtract row a from row b, the coefficient for the term in question becomes zero.
, such that, when we subtract row a from row b, the coefficient for the term in question becomes zero.
Because of the mechanics of matrix multiplication,
- the column of that is modified to make determines which row in is multiplied, and
- the row of that is modified to make determines which row in the recently multiplied row is subtracted from
Hopefully, applying this algorithm to the augmented matrix example we’ve recently considered will make the meaning of this jumble of words more clear.
In that example, we want to multiply the first row of by 4 and subtract it from the second row of . To do this,
- we modify the column 1 of (because row 1 of is the row we want to multiply); then
- we modify row 2 of column 1 of because row 2 of is the row we want to subtract row 1 from
- That is, we modify the
 entry of
entry of
How do we modify this entry? By replacing the existing 0 at  with our multiplier, . And what is in this case? Well, we want to multiply row 1 by 4 so the magnitude of is 4; and we want to subtract row 1 from row 2 so we make negative (i.e.,
with our multiplier, . And what is in this case? Well, we want to multiply row 1 by 4 so the magnitude of is 4; and we want to subtract row 1 from row 2 so we make negative (i.e.,  ).
).
In matrix format, here’s the transformation we made in to get (which we’ll call  to reflect the column and row we manipulated):
to reflect the column and row we manipulated):
![\[ \begin{bmatrix}1&0&0\\0&1&0\\0&0&1\end{bmatrix} \rightarrow \begin{bmatrix}\,\,\,\,\,1&0&0\\-4&1&0\\\,\,\,\,\,0&0&1\end{bmatrix} \]](https://www.samartigliere.com/wp-content/ql-cache/quicklatex.com-b4e49100947d0e55116f1e74e78d94ce_l3.png "Rendered by QuickLaTeX.com")
Now multiply  . The mechanics of doing this should give a clearer picture of why the elimination matrix does what it does:
. The mechanics of doing this should give a clearer picture of why the elimination matrix does what it does:
![\[ \begin{bmatrix}\,\,\,\,\,1&0&0\\-4&1&0\\\,\,\,\,\,0&0&1\end{bmatrix}\begin{bmatrix} 1&2&2&1\\4&8&9&3\\0&3&1&1 \end{bmatrix}=\begin{bmatrix} 1&2&1&\,\,\,\,\,1\\0&0&1&-1\\0&3&2&\,\,\,\,\,1 \end{bmatrix} \]](https://www.samartigliere.com/wp-content/ql-cache/quicklatex.com-db2ee08c2a32594a6085e998e4309235_l3.png "Rendered by QuickLaTeX.com")
As alluded to above, we can also make a matrix, (called a permutation matrix) that will operate on a matrix to bring about a row exchange in that matrix. Again, this is done by modifying the identity matrix, . Specifically, because, just as with elimination matrices, columns affect rows and rows affect columns, to swap 2 rows, we look for columns with the same numbers as the rows that we want to swap, then switch the position of the 1’s in those columns, keeping those 1’s in the same row.
To illustrate this, we’ll stick with the example on which we’ve been working. In this example, we want to exchange rows 2 and 3. To create a matrix that makes this change, we find the columns of the same number as the rows we want to exchange-that would be columns 2 and 3. The 1 in column 2 is in row 2. To facilitate the row exchange, we move that 1 from the second to third column of row 2. This is because, when each column of is dotted with the second row of , the only term that will produce anything other that 0 is the third term, the term that contains a 1 times a contribution from the third row of . When this occurs, the entry from the third row of becomes the corresponding column of row 2 in a new matrix that is the product of and .
Likewise, the 1 in column 3 is in row 3. To finish making our permutation matrix, we take that 1 and move it from the third to the second column of row 3. By doing this, when we dot each column of with the third row of , the only term that produces any output to the new matrix is the second term. That’s because the second column of contains the 1; the other columns of the third row of contain 0’s and output nothing to the new matrix. And because that 1 is in the second column, it “selectively outputs” the values of row 2 of to row 3 of the new matrix.
As in the case of application of the elimination matrix, the above words are just gibberish until we actually see the matrices and perform the manipulations for ourselves:
![\[ \begin{bmatrix} 1&0&0\\0&0&1\\0&1&0 \end{bmatrix}\begin{bmatrix} 1&2&2&\,\,\,\,\,1\\0&0&1&-1\\0&3&2&\,\,\,\,\,1 \end{bmatrix}=\begin{bmatrix} 1&2&2&\,\,\,\,\,1\\0&3&2&\,\,\,\,\,1\\0&0&1&-1 \end{bmatrix} \]](https://www.samartigliere.com/wp-content/ql-cache/quicklatex.com-5072cf0bcae57b27285479675faa2aa3_l3.png "Rendered by QuickLaTeX.com")
The total solution to this problem we’ve been working on with elimination and permutation matrices can be written as follows:

The convention used in Strang’s text is that  is the row we’re multiplying and
is the row we’re multiplying and  is the equation we’re subtracting from. The order of the subscripts associated with the permutation matrix,
is the equation we’re subtracting from. The order of the subscripts associated with the permutation matrix,  and
and  , doesn’t matter.
, doesn’t matter.
Recall that the order of multiplication of the matrices in this expression does matter. The multiplication steps need to be carried out right to left.
Recall, also, that  and
and  can be multiplied together to form a new matrix-let’s call it without subscripts. Then,
can be multiplied together to form a new matrix-let’s call it without subscripts. Then,
 :
:

And

Non-square matrices
So far, all of the matrices we’ve been working with have been square matrices-that is, matrices with the same number of rows and columns. Obviously, there are many occasions where there are either more rows than columns or more columns than rows. We can still do elimination. Instead of there being pivots on diagonal elements, the matrix looks more like a staircase but still with numbers in the right upper aspect and zeros in the lower left portion. We called the upper triangular matrix we obtained after elimination (and from which we solved our system of equation, if a solution existed) U. We call the matrix we obtain after elimination with a rectangular matrix an echelon form of . We still call the nonzero entries of each row pivots. If we reduce the matrix further such that the pivots of the echelon matrix equal 1, then we call such a matrix the reduced row echelon matrix form (rref or R). Here is an example:

Subtract 3 times row 1 from row 2:
echelon form of 
Subtract row 2 of from row 1 of then divide row 2 of by 2. We get:

Special solutions
Here’s another example. Consider the following matrix:

We want to find the null space (see below) of this matrix (that is, all of the solutions for that solve the following equation:  ).
).
We perform elimination. First, subtract 2 times row 1 from row 2 and 3 times row 1 from row 3. That gives us

Subtract row 2 from row 3. That leaves

Divide row 2 by 4:

We have a row of 0’s so we know that there are an infinite number of solutions to this equation but let’s try to be a bit more specific. We note that we have two pivots (a nonzero number in a row with no other nonzero numbers to its left). We also have two columns that contain no pivots (columns 2 and 4). If the vector that we’re multiplying by has components  , then the components that multiply the non-pivot columns, and , are called free variables. To get the solution we want, called special solutions, we
, then the components that multiply the non-pivot columns, and , are called free variables. To get the solution we want, called special solutions, we
- take a non-pivot variable
- assign that variable a value of 1 and assign a value of 0 to all of the other free variables
- back-substitute those values into the nonzero rows of or
 ; that yields one special solution
; that yields one special solution - to find the others, repeat the above process with each of the other free variables
In our case,

Choose  and
and  . We get
. We get

So the first special solution is 
Next, choose  and
and  . That gives us
. That gives us

So the second special solution is 
The complete special solution, then, is

Inverse matrix
The relationship between matrix type (i.e., singular vs. nonsingular) and the inverse matrix merits some discussion. But before we can actually discuss this, we need to lay some groundwork.
Definitions:
Definition 1: If  and
and  then is called the inverse of and the matrix is referred to as being invertible. The symbol for the inverse of
then is called the inverse of and the matrix is referred to as being invertible. The symbol for the inverse of  . So
. So  and
and  . Here’s an example:
. Here’s an example:

Definition 2: A square matrix (i.e., # of rows = # of columns) is nonsingular iff (if and only if) the only solution to  is
is  . Otherwise, is singular.
. Otherwise, is singular.
Proofs:
If and are square matrices that are nonsingular, then is also nonsingular.
(taken from https://yutsumura.com/two-matrices-are-nonsingular-if-and-only-if-the-product-is-nonsingular/#more-4875)
 . Let
. Let  . Then
. Then  . Because
. Because  must be the zero vector. Thus,
must be the zero vector. Thus,  Since
Since If is nonsingular, then is nonsingular.
(taken from https://yutsumura.com/two-matrices-are-nonsingular-if-and-only-if-the-product-is-nonsingular/#more-4875)
 .
.  .
. .
.  . We are given that
. We are given that  ,
,  . That means that
. That means that If is nonsingular, then the columns of are linearly independent.
(taken from https://yutsumura.com/two-matrices-are-nonsingular-if-and-only-if-the-product-is-nonsingular/#more-4875)
 nonsingular matrix. Let
nonsingular matrix. Let  be the
be the  .
. , where
, where![A=\left[ A_1,A_2 \dots A_n\right] \quad \text{and} \quad \vec x=\begin{bmatrix} x_1\\x_2\\ \vdots \\ x_n \end{bmatrix}](https://www.samartigliere.com/wp-content/ql-cache/quicklatex.com-a778942c5129243fbfa198834b53853c_l3.png "Rendered by QuickLaTeX.com")
 ; all of the coefficients of
; all of the coefficients of is nonsingular iff has a unique solution for  .
.
(taken from https://yutsumura.com/two-matrices-are-nonsingular-if-and-only-if-the-product-is-nonsingular/#more-4875)
 . Then
. Then ![A=\left[A_1A_2\dotsA_n\right]](https://www.samartigliere.com/wp-content/ql-cache/quicklatex.com-8f718e98db24673a1e31548d40f6c449_l3.png "Rendered by QuickLaTeX.com") where
where  contains
contains  vectors in
vectors in  . Thus, the vectors in this set must be linearly dependent. Why? Because there can be only
. Thus, the vectors in this set must be linearly dependent. Why? Because there can be only  such that
such that and not every
and not every  can’t be equal to 0. Why? Well, suppose
can’t be equal to 0. Why? Well, suppose  . That means that
. That means that  From our argument above, that would mean-because
From our argument above, that would mean-because  . But that contradicts our statement that not all of the
. But that contradicts our statement that not all of the  .
.![\[\vec b = -\frac{c_1}{c_{n+1}}A_1 - \cdots - \frac{c_n}{c_{n+1}}A_n\]](https://www.samartigliere.com/wp-content/ql-cache/quicklatex.com-c36a8820c130e8497ef73d8d1ef79064_l3.png "Rendered by QuickLaTeX.com")
![\[x_i= - \frac{c_i}{c_{n+1}}\]](https://www.samartigliere.com/wp-content/ql-cache/quicklatex.com-3171409fa73ee403fb69ac8d19a9d005_l3.png "Rendered by QuickLaTeX.com")
 has a unique solution. Suppose
has a unique solution. Suppose  and
and  are solutions. We have
are solutions. We have . Therefore,
. Therefore, . That is,
. That is, If is nonsingular, then is invertible
(taken from https://yutsumura.com/a-matrix-is-invertible-if-and-only-if-it-is-nonsingular)
 be an
be an  has a unique solution
has a unique solution  for
for ![B=\left[\vec x_1\vec x_2\dots\vec x_n\right]](https://www.samartigliere.com/wp-content/ql-cache/quicklatex.com-0e210ed72cf762b454056aa4ca3d952e_l3.png "Rendered by QuickLaTeX.com") . Then
. Then ![AB=\left[\vec e_1\vec e_2\dots\vec e_n\right]](https://www.samartigliere.com/wp-content/ql-cache/quicklatex.com-173cc1bc5a3b70e3a934832a7aa5c8e0_l3.png "Rendered by QuickLaTeX.com") . But
. But ![\left[\vec e_1\vec e_2\dots\vec e_n\right]=I_n](https://www.samartigliere.com/wp-content/ql-cache/quicklatex.com-04a16b1aeec99f6144b1ad0f130aaa88_l3.png "Rendered by QuickLaTeX.com") (i.e., the identity matrix). So
(i.e., the identity matrix). So  can equal the zero vector is if
can equal the zero vector is if  , here, we wind up with
, here, we wind up with  .
. . To do this, multiply
. To do this, multiply  .
. . Therefore,
. Therefore,  .
.If is invertible, then is nonsingular
(taken from https://yutsumura.com/a-matrix-is-invertible-if-and-only-if-it-is-nonsingular)
 . Multiply both sides by
. Multiply both sides by 
If is nonsingular, then is also nonsingular.
(taken from https://yutsumura.com/two-matrices-are-nonsingular-if-and-only-if-the-product-is-nonsingular/#more-4875)
 .
.  is nonsingular. Since
is nonsingular. Since 
If is singular, then is singular
(taken from href=”https://users.math.msu.edu/users/hhu/309/3091418.pdf
 (i.e.,
(i.e.,  ).
). , then
, then 
 , that means that
, that means that  has a nontrivial solution. (Nontrivial means that
has a nontrivial solution. (Nontrivial means that  .)
.)If is singular, then is singular
 ,
,  . We know from above that
. We know from above that 
 , by definition,
, by definition, If is singular, then either , or both are singular
Calculating A-1: Gauss-Jordan elimination
Technique
The inverse of a matrix can be calculated in various ways. A common method is Gauss-Jordan elimination. The basic idea is this: for some  matrix, ,
matrix, ,
- We want to find a matrix,
 , such that
, such that 
- This is tantamount to solving the following equation
- To solve this equation, we need to multiply each column of , (which we’ll call
 ) with to get the corresponding column of (which we’ll call
) with to get the corresponding column of (which we’ll call  ). Thus, we need to solve
). Thus, we need to solve  .
. - How do we do this? By elimination.
- We set up an augmented matrix with on the left and on the right, then proceed with elimination, as usual, until we have an upper triangular matrix on the left and a modification of the identity matrix on the right-a thing that looks something like this:
![\left[\begin{array}{ccc|ccc}x&x&x&1&0&0\\0&x&x&y&1&0\\0&0&x&y&y&1\end{array}\right]](https://www.samartigliere.com/wp-content/ql-cache/quicklatex.com-cc6d0965ada7ba51e8c79645314a0e8f_l3.png "Rendered by QuickLaTeX.com")
- We then continue with elimination, adding/subtracting lower rows from upper rows from on the left side, until we get something that looks like this:
![\left[\begin{array}{ccc|ccc}x&0&0&u&u&u\\0&x&0&u&u&u\\0&0&x&u&u&u\end{array}\right]](https://www.samartigliere.com/wp-content/ql-cache/quicklatex.com-54d1cd642e09459cb8082ebd5f079def_l3.png "Rendered by QuickLaTeX.com")
- We then divide each row by . We are left with something like this:
![\left[\begin{array}{ccc|ccc}1&0&0&v&v&v\\0&1&0&v&v&v\\0&0&1&v&v&v\end{array}\right]](https://www.samartigliere.com/wp-content/ql-cache/quicklatex.com-ed84f594fc0a274d8e0917482c98b441_l3.png "Rendered by QuickLaTeX.com")
- Recall that each elimination step can be represented by a matrix,
 . So what we’ve really done here is multiplied the augmented matrix we started with by
. So what we’ve really done here is multiplied the augmented matrix we started with by  ,
,  ,
, 
 .
. - But also remember that multiplying by several elimination matrices is equivalent to multiplying by a single combined matrix that is the product of those elimination matrices. In this case, that combined matrix is .
- So we started with
![\left[\begin{array}{c|c}A&I\end{array}\right]](https://www.samartigliere.com/wp-content/ql-cache/quicklatex.com-013c50311099dacfb541f95d770cd738_l3.png "Rendered by QuickLaTeX.com") and ended with
and ended with ![\left[\begin{array}{c|c}I&A^{-1}\end{array}\right]](https://www.samartigliere.com/wp-content/ql-cache/quicklatex.com-e4c73b7b5805ffa639ba91dc0eba2e04_l3.png "Rendered by QuickLaTeX.com")
- How did we do this? We multiplied by , , = :
![A^{-1}\left[\begin{array}{c|c}A&I\end{array}\right]=\left[\begin{array}{c|c}I&A^{-1}\end{array}\right]](https://www.samartigliere.com/wp-content/ql-cache/quicklatex.com-7cfec4e9fcd0a34ea67f6ef6b782dd54_l3.png "Rendered by QuickLaTeX.com")

Example
Here is an example (taken from Strang, p. 84) to illustrate the technique:
![\begin{array}{rcl}\left[A\,\,\mathbf{e_1}\,\,\mathbf{e_2}\,\,\mathbf{e_3}\right]&=&\begin{bmatrix} \,\,\,\,\,2&-1&\,\,\,\,\,0&1&0&0\\-1&\,\,\,\,\,2&-1&0&1&0\\ \,\,\,\,\,0&-1&\,\,\,\,\,2&0&0&1 \end{bmatrix}\textbf{ Start Gauss-Jordan on A}\\ \,&\,&\, \\ &\rightarrow &\begin{bmatrix} \,\,\,\,\,2&-1&\,\,\,\,\,0&1&0&0 \\ \,\,\,\,\,\mathbf{0}&\,\,\,\,\,\mathbf{\frac32}&\mathbf{-1}&\mathbf{\frac12}&\mathbf{1}&\mathbf{0}\\ \,\,\,\,\,0&-1&\,\,\,\,\,2&0&0&1 \end{bmatrix}\,\, \frac12\textbf{ row 1}+\textbf{ row 2} \\ \,&\,&\, \\ U &=& \begin{bmatrix} \,\,\,\,\,2&-1&\,\,\,\,\,0&1&0&0 \\ \,\,\,\,\,0& \,\,\,\,\,\frac32&-1&\frac12&1&0\\ \,\,\,\,\,\mathbf{0}&\,\,\,\,\,\mathbf{0}&\,\,\,\,\,\mathbf{\frac43}&\mathbf{\frac13}&\mathbf{\frac23}&\mathbf{1} \end{bmatrix}\,\, \frac23}\textbf{ row 2}+\textbf{ row 3} \\ &\rightarrow& \begin{bmatrix} \,\,\,\,\,2&-1&\,\,\,\,\,0&1&0&0 \\ \,\,\,\,\, \mathbf{0}& \,\,\,\,\,\mathbf{\frac32}&\,\,\,\,\,\mathbf{0}&\mathbf{\frac34}&\mathbf{\frac32}&\mathbf{\frac34}\\ \,\,\,\,\,0&\,\,\,\,\,0&\,\,\,\,\,\frac43&\frac13&\frac23&1 \end{bmatrix}\,\, \frac34}\textbf{ row 3}+\textbf{ row 2} \\ \,&\,&\, \\ &\rightarrow& \begin{bmatrix} \,\,\,\,\,\mathbf{2}&\,\,\,\,\,\mathbf{0}&\,\,\,\,\,\mathbf{0}&\mathbf{\frac32}&\mathbf{1}&\mathbf{\frac12} \\ \,\,\,\,\, 0& \,\,\,\,\,\frac32&\,\,\,\,\,0&\frac34&\frac32&\frac34\\ \,\,\,\,\,0&\,\,\,\,\,0&\,\,\,\,\,\frac43&\frac13&\frac23&1 \end{bmatrix} \,\,\, \begin{matrix} \textbf{divide by }2 \, \\ \textbf{divide by }\frac32 \\ \textbf{divide by }\frac43 \\ \end{matrix} \\ \,&\,&\, \\ &\rightarrow& \begin{bmatrix} \,\,\,\,\,\mathbf{1}&\,\,\,\,\,0&\,\,\,\,\,0&\mathbf{\frac34}&\mathbf{\frac12}&\mathbf{\frac14} \\ \,\,\,\,\, 0& \,\,\,\,\,\mathbf{1}&\,\,\,\,\,0&\mathbf{\frac12}&\mathbf{1}&\mathbf{\frac12}\\ \,\,\,\,\,0&\,\,\,\,\,0&\,\,\,\,\,\mathbf{1}&\mathbf{\frac14}&\mathbf{\frac12}&\mathbf{\frac34} \end{bmatrix} \,\,\,\begin{matrix} \text{=}&\left[I\,\,\mathbf{x_1}\,\,\mathbf{\,x_2}\,\,\mathbf{x_3}\right]&\text{=}\,\,\left[I\,\,A^{-1}\right] \end{matrix} \end{array}](https://www.samartigliere.com/wp-content/ql-cache/quicklatex.com-0288bec0e42c4d3e6524763213e32fc8_l3.png "Rendered by QuickLaTeX.com")
So

Just a quick glimpse at a topic that will by considered in depth shortly: note that,
- The product of the pivots of ,
 . This product, , is called the determinant of .
. This product, , is called the determinant of . - involves division by the determinant

One final comment regarding Gauss-Jordan elimination that may seem obvious, but just a reminder: Gauss-Jordan elimination can only be applied to a matrix to find its inverse if the matrix
- is nonsingular (since nonsingular matrices are the only type of matrix that have an inverse) and
- is a square matrix (since the only type of matrix that can be nonsingular is a square matrix)
Now that we have discussed singular, nonsingular and inverse matrices, a few miscellaneous topics regarding the solutions to matrix equations need to be discussed.
PA = LU
A significant issue in linear algebra is attempting to solve the equation  . To do this, we apply Gaussian elimination. In Gaussian elimination, each step can be affected by multiplying a matrix, , on the left, times and
. To do this, we apply Gaussian elimination. In Gaussian elimination, each step can be affected by multiplying a matrix, , on the left, times and  . So we have,
. So we have,
![\[ \underbrace{E_n\,\dots\,E_2\,E_1\,A}_{U}\underbrace{\mathbf{x}}_{\mathbf{x}}=\underbrace{E_n\,\dots\,E_2\,E_1\,\mathbf{b}}_{\mathbf{c}} \]](https://www.samartigliere.com/wp-content/ql-cache/quicklatex.com-36f2eb8f7e88953e4bb4e24942fdd748_l3.png "Rendered by QuickLaTeX.com")
Note that in the above equation, as discussed in the section on the commutation relationship between matrices, the order in which we multiply the ‘s matters. Based on what we learned in the section on inverse matrices, we know that we can get back by multiplying both sides of the equation by the inverse of , which we’ll call  (because it turns out that is always lower triangular):
(because it turns out that is always lower triangular):

Let’s let  be the product of the elimination matrices. From the above equation, we can see that,
be the product of the elimination matrices. From the above equation, we can see that,
 and
and  so
so  .
.
Let’s look at a couple of examples:
Consider the matrix  . We perform elimination on this matrix by subtracting 3 times row 1 from row 2. The matrix that does this is
. We perform elimination on this matrix by subtracting 3 times row 1 from row 2. The matrix that does this is  . We have
. We have

To get back from to , we multiply by the inverse of  ,
,  :
:

So


Notice that the inverse of our elimination matrix,  (or ) is just our elimination matrix,
(or ) is just our elimination matrix,
Another way of looking at it is  and
and  .
.
Substitute  for
for  in . That leaves
in . That leaves  .
.
But we also know that . That means that  which means that
which means that  .
.
Another form of that some authors use is  . (As will become evident below, the equation should more correctly be written
. (As will become evident below, the equation should more correctly be written  but is the way most authors refer to it so we’ll stick with that.) In this form, we split into two matrices, one a diagonal matrix,
but is the way most authors refer to it so we’ll stick with that.) In this form, we split into two matrices, one a diagonal matrix,  that has the pivots of on its diagonals and a variant of (let’s call it
that has the pivots of on its diagonals and a variant of (let’s call it  ) that has all 1’s on its diagonals. When we multiply
) that has all 1’s on its diagonals. When we multiply  we get back :
we get back :

Extending the example we’ve already seen:

represents elimination without row exchanges. If we do our row exchanges before elimination, then  where represents the product of all of the permutation matrices used to carry out the row exchanges. As we’ll see, this equation, , will become useful shortly.
where represents the product of all of the permutation matrices used to carry out the row exchanges. As we’ll see, this equation, , will become useful shortly.
Solving matrix equations 2
There are a few things that can be gleaned by examining , or  .
.
First, by way of review,
- (short for upper triangular) is the matrix we get after application of Gaussian elimination to a square (
 by ) matrix.
by ) matrix. - An echelon matrix is what we get after Gaussian elimination is performed on a rectangular matrix (i.e., an by matrix where
 ).
). - R is the row reduced echelon form () of a matrix after we’ve performed eliminations steps until all of the pivots are 1’s.
- The pivots are the first non-zero entries on each row of , the echelon form of or .
Then for a matrix, , that is reduced to , or :
- If there are nonzero entries on all of the diagonals of (i.e., all of the diagonal elements are pivots), then the matrix from which came is nonsingular. There will be a unique solution to
 .
. - If there are any zeros along the diagonal of , then is singular. There will be none or many solutions to .
- If there is one or more rows of zeros in , then is singular.
- If there is a row or column of zeros in , then the entries of the analogous row or column in are linearly dependent; on the other hand, if a row of has a pivot, then its entries are linearly independent.
Transpose of a matrix, AT
The transpose of matrix is depicted by the mathematical symbol  and is the result of swapping the rows and columns of . For example:
and is the result of swapping the rows and columns of . For example:

An important theorem related to the transpose of matrices is its product rule:

 be an
be an 

![\[ (A\mathbf{v})^T=\mathbf{v}^TA^T \]](https://www.samartigliere.com/wp-content/ql-cache/quicklatex.com-dee2314a418d793d44277f162a975437_l3.png "Rendered by QuickLaTeX.com")


 , is also equal to the
, is also equal to the 

 is analogous to
is analogous to  . But the
. But the  is just the
is just the 
Here are two example designed to further show that this theorem works:





Vector Subspaces
Subspaces of a vector space, called vector subspaces, are an important topic that I don’t devote nearly enough time to in this article. However, here are some basic facts about them. For a given matrix, :
- its column space is the set of all possible solutions (=vectors) that can be produced from all possible linear combinations of the columns of . It is represented symbolically as
 .
. - its row space is the set of all possible solutions (=vectors) that can be produced from all possible linear combinations of the rows of . It is represented symbolically as
 where is the transpose of . The reason that this is true is because, by definition, when matrix is transposed, its rows become its columns. Thus, when we take all of the possible linear combinations of the columns of , what we’re really doing is taking all of the linear combinations of the rows of the original matrix, .
where is the transpose of . The reason that this is true is because, by definition, when matrix is transposed, its rows become its columns. Thus, when we take all of the possible linear combinations of the columns of , what we’re really doing is taking all of the linear combinations of the rows of the original matrix, . - its nullspace is the set of all vectors, , such that , 0 meaning the so-called zero vector, a vector with all 0’s for coefficients.
- its left nullspace is the set of all vectors, , such that
 , 0, again, representing the zero vector
, 0, again, representing the zero vector
There are two important properties associated with vector subspaces – dimension and rank. Here are a few facts about them:
- The rank of a matrix is the number of pivots in the matrix.
- The number of vectors in the basis of a vector space or subspace equals the number of pivots.
- The dimension of a subspace is the number of vectors in a basis.
- The rank of a matrix, , determines the dimensions of the fundamental subspaces of the matrix.
If the matrix has rows and columns, then,
- The number of dimensions of both the row space and column space of equal its rank,
 .
. - The number of dimensions of the nullspace of is
 . This is because the nullspace is defined by the solutions to the equation
. This is because the nullspace is defined by the solutions to the equation  , i.e., called special solutions. Recall from our discussion of special solutions that these solutions come from the free variables and there are of them. The column vectors associated with these special solutions form a basis for the null space.
, i.e., called special solutions. Recall from our discussion of special solutions that these solutions come from the free variables and there are of them. The column vectors associated with these special solutions form a basis for the null space. - The number of dimensions of the left nullspace of is
 . The reason is similar to that for the nullspace. The left nullspace is defined as the solutions to the equation
. The reason is similar to that for the nullspace. The left nullspace is defined as the solutions to the equation  . These solutions are the special solutions for this equation and come from the free variables. Since is transposed, the number of these free variables equals the number of columns of , (which, because of the transpose, equals the number of rows of ) minus the number of pivots, (which also equals the rank).
. These solutions are the special solutions for this equation and come from the free variables. Since is transposed, the number of these free variables equals the number of columns of , (which, because of the transpose, equals the number of rows of ) minus the number of pivots, (which also equals the rank).
Projections

Projection of a vector onto a line or a plane are two important concepts that have many applications in math and science. Thus, they need to be discussed here. This discussion is taken from Strang’s textbook, pages 207-210.
Projection onto a line
Consider a vector,  , that passes through the origin. It could be in any number of dimensions but, for simplicity, we’ll consider and example in 2 dimensions. We want to project another vector,
, that passes through the origin. It could be in any number of dimensions but, for simplicity, we’ll consider and example in 2 dimensions. We want to project another vector,  , onto and come up with a formula for this projection. To do this, we create a vector perpendicular to with its origin at the tip of and its tip at the point where it intersects the line spanned by . We’ll call this vector
, onto and come up with a formula for this projection. To do this, we create a vector perpendicular to with its origin at the tip of and its tip at the point where it intersects the line spanned by . We’ll call this vector  (“e” as in error or spatial discrepancy between the end of and ). The vector it creates along – between the origin and the point where intersects the line that spans – is the projection vector
(“e” as in error or spatial discrepancy between the end of and ). The vector it creates along – between the origin and the point where intersects the line that spans – is the projection vector  . It can be specified by the equation
. It can be specified by the equation  where is some constant that serves as a scaling factor. We can see from the equation that if
where is some constant that serves as a scaling factor. We can see from the equation that if  then
then  . If
. If  then
then  . And if
. And if  then .
then .
By the definition of vector subtraction,
 . (To see this, click .)
. (To see this, click .)

Now is perpendicular to . Therefore,

Because

That means that,
 .
.
Projection onto a plane
To be added later
Projection onto a vector space
To be added later
Geometric Interpretation of the dot product
As we did previously with vector equations and matrix multiplication, we can use the concept of linear transformations to gain a better understanding of why the dot product formulas are what they are. In the linear transformations created by a matrix, the columns of a matrix can be thought of as representing unit vectors for a coordinate system. The process of taking the dot product can be thought of in a similar way except that each column of the matrix that brings about the linear transformation that constitutes the dot product consists of just one coordinate (i.e., they are one dimensional).
So, for example, if we want to take the dot product of  and
and  , we use as a matrix with columns
, we use as a matrix with columns  and (also called a row vector) and multiply this matrix with the column vector :
and (also called a row vector) and multiply this matrix with the column vector :

When we discussed multiplication of a matrix times a vector, we said, for example, that the left-hand column of the matrix specifies where the unit vector along the x-axis in a Cartesian coordinate system, , “lands” after the matrix column brings about its linear transformation. Likewise, the right-hand column specifies where the unit vector along the y-axis in a Cartesian coordinate system, , “lands” after the matrix column brings about its linear transformation. In taking the dot product, the left-hand column of the one-row matrix (i.e., row vector) that brings about the linear transformation is just a number. That number specifies the length of a vector on a line that begins at the origin, , and ends on the number given by the vector’s length. This vector-on-a-line can be thought of as the “new ”. Similarly, the right-hand column of the one-row matrix (i.e., row vector) that brings about the linear transformation specifies the length of a vector on a line (the same line on which the “new ” lies). This vector begins at the origin, , and ends on the number, again, given by the vector’s length. This vector-on-a-line can be thought of as the “new” . We then perform matrix vector multiplication just like we did previously:
- Multiply the upper component of the vector we want to take the dot product with times the “new ”
- Multiply the lower component of the vector we want to take the dot product with times the “new ”
- Add the vectors end to end.
The result of this process ends on a number-essentially, a number on a number line. Thus, we’ve taken two vectors (2-dimensional objects) and reduced them to a scalar (a 1-dimensional object).
The following diagrams illustrate this process using the example we were just considering:

In this figure, the 1-column matrix (or row vector)  transforms into a vector 3 units long on the number line (figure a) and into a vector 2 units long on the number line (figure b). Both point in the same direction, on the same line, the number line.
transforms into a vector 3 units long on the number line (figure a) and into a vector 2 units long on the number line (figure b). Both point in the same direction, on the same line, the number line.

Referring to the figure above labeled c, the dot product is then performed like any other matrix-vector multiplication. In this case, , which is 3 units long and starts from the origin, would end on 3. , which is 2 units long, is multiplied by 2 giving us a vector 4 units long. This vector is laid end-to-end with the first vector. When we do this, the second vector ends up on 7, which is our answer.
Here’s another example.

 . would be the same but would be a vector 2 units long pointing in the opposite direction along the number line. If we take the dot product of this vector with vector (1,2), we get
. would be the same but would be a vector 2 units long pointing in the opposite direction along the number line. If we take the dot product of this vector with vector (1,2), we get  .
.
The discussion presented above explains the general formula for the dot product. But is there a geometric interpretation for the formula for the dot product that involves vector projections and cosines? The answer is yes. It can be visualized as follows:
As shown below, we place a line through one of the vectors that we want to include in a dot product calculation, in this case the vector,  drawn in blue in the diagram. Then we examine the unit vector associated with and the line it spans (depicted in green):
drawn in blue in the diagram. Then we examine the unit vector associated with and the line it spans (depicted in green):

A closer look at the unit vector,  , shows that it has components
, shows that it has components  and
and  .
.

Now project (shown in blue in the diagram below) onto . A triangle is formed by , its projection on and the dotted line perpendicular to that projection. is the hypotenuse. It’s length, given that it’s a unit vector, is 1 unit. Therefore, the projection, labeled  , equals
, equals  . This explains why the projection of onto is labeled . It’s because it is .
. This explains why the projection of onto is labeled . It’s because it is .
Similarly, (depicted in red in the diagram below), the projection of onto and the dashed line connecting the two of them form a triangle, being the hypotenuse. And like , since it’s a unit vector, its length is 1 unit. The projection of onto then equals  . Therefore, the projection of onto is the same as
. Therefore, the projection of onto is the same as  and is labeled as such.
and is labeled as such.
The process we’ve just described is a transformation that takes to and to . But this process of taking a 2-dimensional vector and translating it onto a 1-dimensional space is analogous to the 1 row matrix (=row vector) we used previously to take the dot product.

Next, take the projection of onto the line that spans. A review of projections can be found here. Recall that the formula for a projection, as it applies to this case, is

But  equals the length of which equals 1. Therefore,
equals the length of which equals 1. Therefore,

 is a number. It is the magnitude of the projection vector, . And the direction of ? This is specified by .
is a number. It is the magnitude of the projection vector, . And the direction of ? This is specified by .
Applying this to the example of projecting  onto (which is the unit vector for ), we have:
onto (which is the unit vector for ), we have:

Using the formula for the projection that we derived, from the diagram above, we can see that

We saw previously that is the projection of (which has length = 1) onto . Therefore,  .
.
Likewise, is the projection of (which has length = 1) onto . Therefore,  .
.

Thus,




And

So is a vector approximately 1.942 units long pointed in the direction of
Now let’s go back to the expression  . We’re talking about the projection of onto as if it were a vector – and it is. But it’s not a vector in 2-dimensional space; it’s a vector in 1-dimensional space, that space being the space along the line that’s the span of . And a one dimensional space is better known as a point – that is, a scalar – which is what the dot product is. Specifically, this process of projecting a vector, , onto another vector, , is equivalent to taking the dot product of with the unit vector of .
. We’re talking about the projection of onto as if it were a vector – and it is. But it’s not a vector in 2-dimensional space; it’s a vector in 1-dimensional space, that space being the space along the line that’s the span of . And a one dimensional space is better known as a point – that is, a scalar – which is what the dot product is. Specifically, this process of projecting a vector, , onto another vector, , is equivalent to taking the dot product of with the unit vector of .
Recall that a vector is just the product of the length of that vector (which is a scalar) times its unit vector, :  . So the expression for the dot product of a vector, with another vector, , is
. So the expression for the dot product of a vector, with another vector, , is

Per the associative property of multiplication for the dot product:

But, from our diagram, it is easy to see that

Therefore, the dot product of with is given by the equation


Let’s check to see that these formulas work by using our example – taking the dot product of and . We have,
- Angle between and the x-axis is

- Angle between and the x-axis is

- Angle between and is



Thus,

And
![\begin{array}{rcl}\vec{v}\cdot\vec{w}&=&(\hat{u}\cdot\vec{w})\lvert \vec{v} \rvert\\&=&(\lvert \vec{w} \rvert \cos{\theta})\lvert \vec{v} \rvert\\&\approx& \left[(2.24)(0.87)^\circ}\right]3.61 \\&\approx& (1.942)(3.61) \\&=& 7\end{array}](https://www.samartigliere.com/wp-content/ql-cache/quicklatex.com-9de5372bf2c8b35735aac8c03d58e9ce_l3.png "Rendered by QuickLaTeX.com")
We can verify that these results are correct by using the standard method of taking the dot product:

Determinants
To quote Wikipedia,
the determinant is a scalar value that can be computed from the elements of a square matrix and encodes certain properties of the linear transformation described by the matrix. The determinant of a matrix A is denoted det(A) or |A|. https://en.wikipedia.org/wiki/Determinant
In discussing the topic of the determinant of a matrix, most authors begin by defining the determinate by its formulas, first for a 2 x 2 matrix, then for the general case of any n x n matrix. They then go on to derive the determinant’s properties by its formulas. Dr. Strang, in contrast, starts by defining a mathematical entity-the determinant-by listing its properties. He then goes on to derive the formulas for that entity from these properties. In my opinion, this latter approach makes it more clear why such formulas “work.” Therefore, the discussion that follows is taken from chapter 5 of Strang’s textbook, cited at the end of this document.
Properties of the determinant
Strang, like other authors, defines 10 properties of the determinant. However, the first 3 are the most important as the other 7 properties can be derived from them. Here are those 3 properties:
1. The determinant of the identity matrix, I, is 1.

2. The determinant changes sign when 2 rows are exchanged.

3. The determinant depends linearly on the first row. That is, if , and are matrices whose rows are the same below the first row, if the first row of is a linear combination of the first rows of and , then the determinant of is the same combination of  and
and  . Since linear combinations involve addition/subtraction and multiplication, this rule can be broken down into 2 parts:
. Since linear combinations involve addition/subtraction and multiplication, this rule can be broken down into 2 parts:
a. Add vectors in row 1

b. Multiply by  in row 1
in row 1

As mentioned above, the remainder of the properties of the determinant can be proven from the first 3. However, for now, I’ll just list them and prove them only as needed.
4. If 2 rows of are equal, the  .
.
 . If we make a row exchange, by rule 2, the sign of the determinant should change. However, when we do this, we get back the same matrix that we started with. But if the pre-row exchange and post-row exchange matrices are the same, they should have the same determinants. So we have
. If we make a row exchange, by rule 2, the sign of the determinant should change. However, when we do this, we get back the same matrix that we started with. But if the pre-row exchange and post-row exchange matrices are the same, they should have the same determinants. So we have  and
and  . The only way that this could be true is if the determinant, D , is zero.
. The only way that this could be true is if the determinant, D , is zero.5. Subtracting a multiple of one row from another row leaves the same determinant.


 has two rows that are the same. Therefore,
has two rows that are the same. Therefore, .
.
6. If has a row of 0’s, then  .
.
 .
. .
. .
. .
. .
.7. If is triangular, the  is the product
is the product  of the diagonal entries. If the triangular matrix has 1’s along the diagonal, the
of the diagonal entries. If the triangular matrix has 1’s along the diagonal, the  .
.














 is the identity matrix,
is the identity matrix,  .
.
8. If is singular, the  . If is nonsingular, the
. If is nonsingular, the  .
.
 , then the equation
, then the equation  , then the equation
, then the equation  . And because
. And because  ,
,  is also 0.
is also 0. . And because
. And because 9. The determinant of is the product of and  .
.






 , consider the ratio
, consider the ratio  . If determinant properties 1, 2 and 3 apply to
. If determinant properties 1, 2 and 3 apply to  then we can say that
then we can say that  and that
and that  .
. , then
, then 
 changes sign and so does the ratio
changes sign and so does the ratio  .
.

![\[t\lvert A \rvert=\frac{t\lvert AB \rvert }{\lvert B \rvert }\quad\Rightarrow \quad\lvert A \rvert=\frac{\lvert AB \rvert }{\lvert B \rvert }\]](https://www.samartigliere.com/wp-content/ql-cache/quicklatex.com-f9fb937e57c39b0858cf57808daf8dcb_l3.png "Rendered by QuickLaTeX.com")
 . After applying rule 3a then dividing by
. After applying rule 3a then dividing by  , the resulting ratios add-which is what we want.
, the resulting ratios add-which is what we want. . This fact will be useful later.
. This fact will be useful later.
 . If this is true then, because of rule 3a,
. If this is true then, because of rule 3a, 

 (i.e.,
(i.e., 10. The transpose of has the same determinant as itself: 
 ,
,  . If we transpose
. If we transpose  ,
,  . So we are left with
. So we are left with  .
.

 with
with  .
.
 both have all 1’s on their diagonals. Therefore by rule 7,
both have all 1’s on their diagonals. Therefore by rule 7,  .
. both have the same diagonal entries. Therefore by rule 7,
both have the same diagonal entries. Therefore by rule 7,  .
.








 and
and  are the same, only way that the above equation can be true is if both
are the same, only way that the above equation can be true is if both  and
and  are +1 or -1.
are +1 or -1.
 . (We’ll see how to calculate such determinants in the next section.)
. (We’ll see how to calculate such determinants in the next section.) . Therefore,
. Therefore, Note that because  , all of the properties that apply to rows also apply to columns. Specifically,
, all of the properties that apply to rows also apply to columns. Specifically,
- The determinate changes when two columns are exchanged.
- A column of all zeros or two equal columns make the determinant zero.
- Linearity (i.e., multiplying by a constant or adding a constant to a column) applies to columns just as it does for rows
Formulas for the determinant
Product of diagonals of a triangular matrix
In our discussion of property 7 of the determinant, we noted that if a matrix is triangular, then the determinant of that matrix is the product of its diagonal elements. Thus, a straightforward way to calculate the determinant of a matrix is to apply row operations on the matrix until it is triangular, then take the product of the diagonals of that matrix. Remember that if we make row exchanges as part of those row operations, we have to change the sign of the determinant each time we make such an exchange. This method is probably the most efficient way to calculate the value of the determinant of a matrix and is the one usually used by computers, especially for large matrices.
The “big” formula
2 x 2 Matrix
Let’s start by deriving the determinant for a 2 x 2 matrix. We can express the matrix  as a linear combination of other matrices:
as a linear combination of other matrices:

By the linearity rule (rule 3a),

Let’s look at  .
.
Multiply the top row of the matrix by  . We get
. We get
 .
.
By rule 4,
 .
.
Therefore,  .
.
 .
.
It follows, then, that  .
.
A similar argument can be made for the matrix  (or for any matrix that has a column of all 0’s, for that matter).
(or for any matrix that has a column of all 0’s, for that matter).
Based on this, we can ignore and in our expression for 
This leaves us with

Now let’s take a look at  .
.
By rule 3b.
 .
.
If we apply rule 3b again, we get
 .
.
Next, let’s examine  .
.
By rule 3b.
 .
.
If we apply rule 3b again, we get

If we exchange the top and bottom rows of  , that leaves us with
, that leaves us with
 .
.
Because of this,

That means that
 .
.
Since
 and
and
the following must be true

This is the general formula for the determinant of a 2 x 2 matrix. And the general procedure for obtaining this formula is to
1. Multiply the top left entry in the matrix by the bottom right entry = product 1
2. Multiply the top right entry by the bottom left entry = product 2
3. Subtract the value of product 2 from that of product 1
A visual depiction of this procedure is shown below in figure 4:
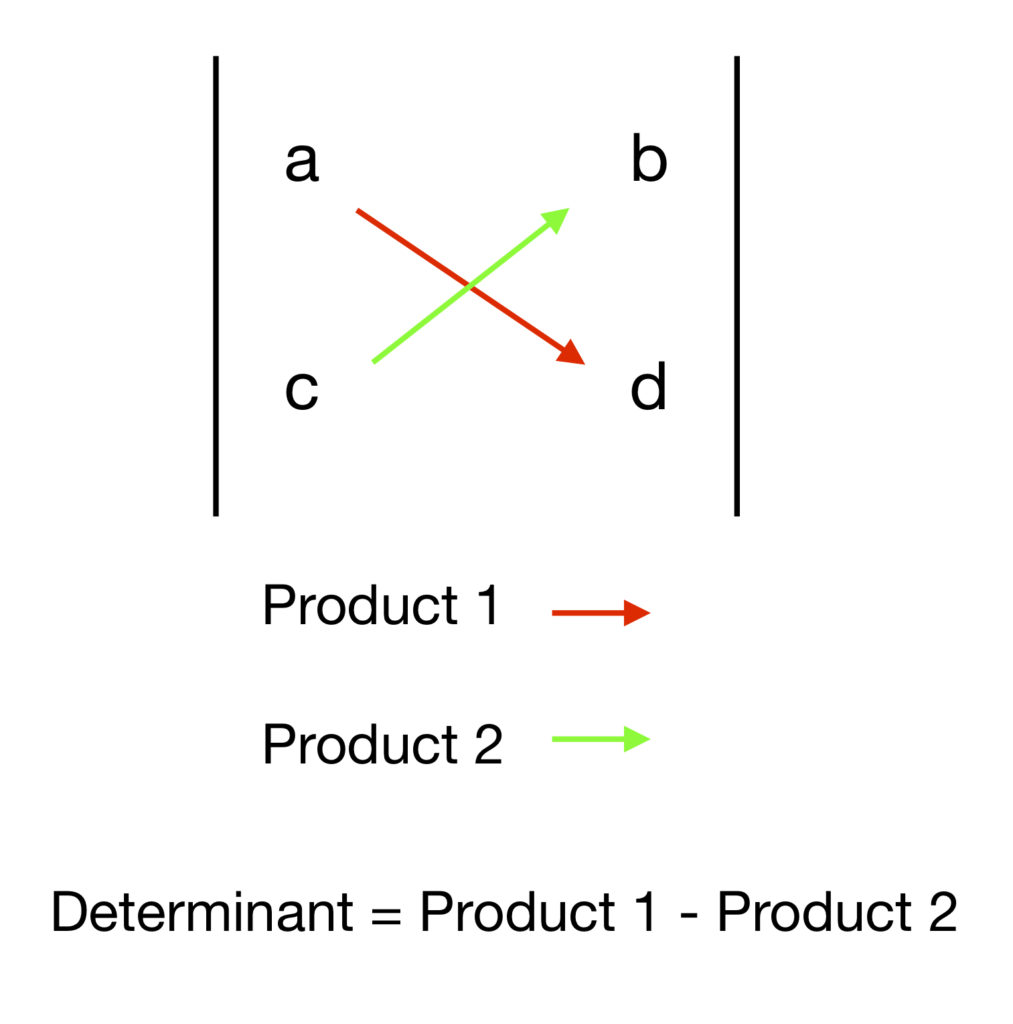
3 x 3 Matrix
Let’s start with the matrix 
By rule 3a (linearity), it’s determinant,  can be broken down into the sum of three other determinants,
can be broken down into the sum of three other determinants,  ,
, and
and  such that,
such that,

, and can be further broken down into the sum of 9 determinants each, as shown in the following three diagrams:



Thus, can ultimately be expressed as a sum of 27 ( ) determinants. However, by determinant property 6, if a matrix has a row of zeros, then its determinant is zero. And by property 10,
) determinants. However, by determinant property 6, if a matrix has a row of zeros, then its determinant is zero. And by property 10,  . This means that a column of zeros in a matrix will also make its determinant zero. Or we could apply the more convoluted argument used in the proof of the 2×2 matrix formula above. Either way, from the above diagrams, it is apparent that 21 out of the 27 determinants that add up to make up have at least one column of zeros. The determinants of these matrices are zero. Thus, only 6 (
. This means that a column of zeros in a matrix will also make its determinant zero. Or we could apply the more convoluted argument used in the proof of the 2×2 matrix formula above. Either way, from the above diagrams, it is apparent that 21 out of the 27 determinants that add up to make up have at least one column of zeros. The determinants of these matrices are zero. Thus, only 6 ( ) of the 27 determinants contribute to .
) of the 27 determinants contribute to .
Let’s take a look at what makes a term zero versus actually contributing to the value of the determinant. Basically, we’re trying to convert the determinants of permutation matrices into the identity matrix by row exchanges. The identity matrix has a 1 in each row and column. All the rest of the entries in the row and column that contains the 1 are zeros. Therefore, to make a row exchange or exchanges that yields the identity matrix, the permutation matrix on which the row exchange is being made must also contain only a single 1 (and all the rest zeros) in each of its rows and columns. In contrast, as stated above, if a permutation matrix contains a row or column of zeros, then its determinant is 0 and it makes no contribution to the overall determinant we are trying to calculate.
As alluded to above, for an 3 x 3 matrix, there are  determinants that contribute to the overall determinant. Why? because, as we’ve already seen, we can break the determinant of that matrix down into the sum of the products of three coefficients times a permutation matrix. If a term in that sum is to contribute to the overall determinant of the original 3×3 matrix, the permutation matrix associated with that term has to have a single one in each of its rows (or, because , its columns). Thus, if such a permutation has a 1 in column 1, there are three possible rows that such a 1 in column 1 can be positioned. For each of these resulting determinants, since row 1 is already “taken,” there are two possible rows in which the second 1 can be positioned, and that leaves one one remaining row in which the third 1 can be positioned. So for each three “subdeterminants,” there are two other configurations in which the 1’s can be positioned and still contribute to the overall determinant of the original 3 x 3 matrix; that’s
determinants that contribute to the overall determinant. Why? because, as we’ve already seen, we can break the determinant of that matrix down into the sum of the products of three coefficients times a permutation matrix. If a term in that sum is to contribute to the overall determinant of the original 3×3 matrix, the permutation matrix associated with that term has to have a single one in each of its rows (or, because , its columns). Thus, if such a permutation has a 1 in column 1, there are three possible rows that such a 1 in column 1 can be positioned. For each of these resulting determinants, since row 1 is already “taken,” there are two possible rows in which the second 1 can be positioned, and that leaves one one remaining row in which the third 1 can be positioned. So for each three “subdeterminants,” there are two other configurations in which the 1’s can be positioned and still contribute to the overall determinant of the original 3 x 3 matrix; that’s  . This argument can be extended to the n x n case. For example, for a 4 x 4 matrix, the number of terms that such a matrix can be broken down into equals
. This argument can be extended to the n x n case. For example, for a 4 x 4 matrix, the number of terms that such a matrix can be broken down into equals  . However, the number of terms that actually contribute to the determinant is
. However, the number of terms that actually contribute to the determinant is  .
.
As seen in the proof of determinant property 7-using determinant property 3b-these 6 determinants can be simplified into the product of three coefficients times the determinant of a permutation of the identity matrix. This determinant can then be turned into the determinant of the identity matrix by making row exchanges. This is done because, by rule 1, the determinant of the identity matrix is 1. Multiplying the expression of the product of the three coefficients times 1 (i.e., the determinant of the identity matrix) leaves just the product of the three coefficients. However, by rule 2, the sign of the determinant changes when row exchanges are made. Thus, if an odd number of row exchanges is required to change the determinant of the permutation of the identity matrix to that of the identity matrix, then the products of coefficients must be multiplied by -1 instead of 1. If an even number of row exchanges are needed, then the coefficients are multiplied by +1.
Here are two examples:
 :
:
 into the determinant of the identity matrix, which we know equals 1. To do this, we exchange rows 1 and 2. But that row exchange changes the sign of the determinant from +1 to -1. Therefore, we are left with
into the determinant of the identity matrix, which we know equals 1. To do this, we exchange rows 1 and 2. But that row exchange changes the sign of the determinant from +1 to -1. Therefore, we are left with
 :
:

 .
.After applying rule 3b to , we get,

Next, perform row exchanges until each determinant in the equation above become the identity matrix. To do this, the first three determinants on the right side of the above equation require zero or two row exchanges. Thus, the product of the three coefficients in these terms are each multiplied by +1. On the other hand, the second three terms in the above equation require one row exchange. Therefore, the product of the three coefficients in these terms are each multiplied by -1. That leave us with,
![\[\begin{array}{rcl}\det{A}&=&a_{11}a_{22}a_{33}+a_{12}a_{23}a_{31}+a_{13}a_{21}a_{32}\\&\,&-a_{11}a_{23}a_{32}-a_{12}a_{21}a_{33}-a_{13}a_{22}a_{31}\end{array}\]](https://www.samartigliere.com/wp-content/ql-cache/quicklatex.com-f7412863a0db8073b1e15fa6f4d17228_l3.png "Rendered by QuickLaTeX.com")
which is the big formula for the determinant of a 3 x 3 matrix.
From the above considerations, we can come up with a general expression for the big formula of a square matrix of any size. Let be a square matrix with columns  . The permutation matrices that cause terms to contribute to the overall determinant are ordered in ways that we will call
. The permutation matrices that cause terms to contribute to the overall determinant are ordered in ways that we will call  where
where  are unique for a given term and specify the rows in the permutation matrix where the 1’s are found.
are unique for a given term and specify the rows in the permutation matrix where the 1’s are found.
For example, for a 3 x 3 matrix, the six possibilities for  are
are  .
.
We’ll follow the nomenclature in Strang’s text and define an entity,  which is basically the +1 or -1 by which we multiply the product of coefficients, an entity determined by how many row exchanges it takes to change a given permutation matrix into the identity matrix.
which is basically the +1 or -1 by which we multiply the product of coefficients, an entity determined by how many row exchanges it takes to change a given permutation matrix into the identity matrix.
In the case of a 3 x 3 matrix, the  values for each permutation matrix are as follows:
values for each permutation matrix are as follows:
 |
 |
 |
|---|---|---|
 |
 |
 |
Then, for an n x n matrix:

The cofactor formula
There are several ways to calculate the determinant of a square matrix. One that we haven’t discussed in detail is to reduce the matrix into reduced row echelon form and take the product of the diagonal elements. By property 7, this is the determinant of the matrix. A second method, which we just outlined, is the big formula. A third method, which we can derive by factoring out terms from the big formula, is the so-called cofactor method, which we present here. We’ll present the formula, then show why it makes sense. A good discussion of this topic can be found at the following source:
https://www.math.purdue.edu/files/academic/courses/2010spring/MA26200/3_3.pdf
Our ideas here will be largely taken from this source. Here goes:
Define an entity called a minor as follows:
Let be an n x n matrix. The minor,  , of an element of ,
, of an element of ,  , is the determinant of the matrix obtained by deleting the th row vector and th column vector of .
, is the determinant of the matrix obtained by deleting the th row vector and th column vector of .
So if 
then, for example

For example, for

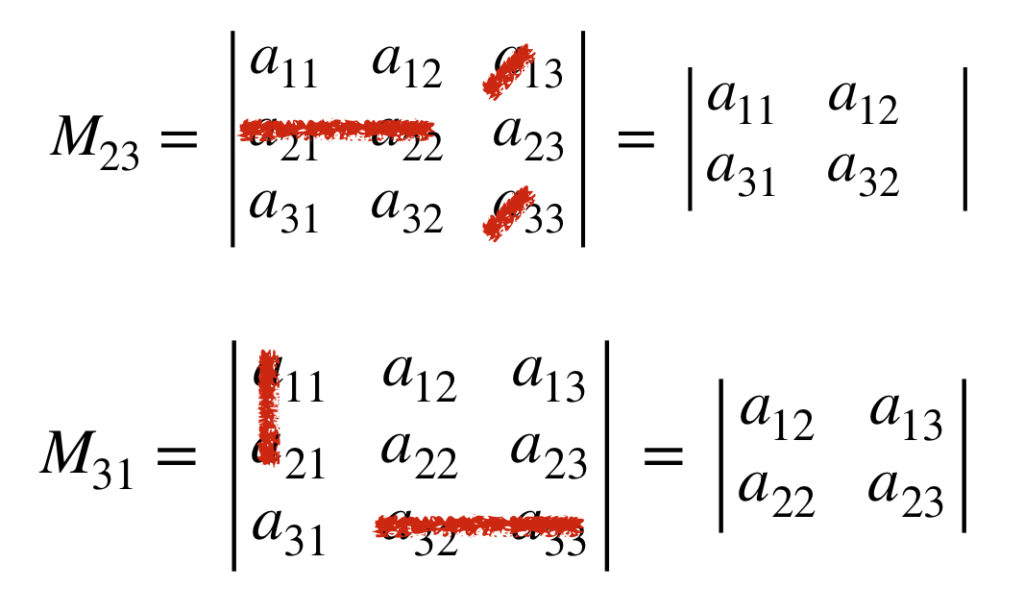
Here’s another definition:
For the same matrix, , the cofactor,  of element , is
of element , is

where is the minor of .
From the above definition, we see that the cofactor of and the minor of are the same if  is even, and differ by a minus sign if is odd. The appropriate sign for the cofactor, is easy to remember because it alternates in the following manner:
is even, and differ by a minus sign if is odd. The appropriate sign for the cofactor, is easy to remember because it alternates in the following manner:

So for matrix 
With these definitions under our belts, we are now ready to state the cofactor formula for the determinant. Here it is:

To see why this works, it is instructive to consider the case of a 3 x 3 matrix. Let 
We’ve already seen that the big formula for this determinant is:
Collecting terms, we have,

The three quantities in parentheses correspond to the cofactors defined above.
If we use determinant property 3a and split  into the three determinants that follow, it is easy to see how the cofactor formula comes about:
into the three determinants that follow, it is easy to see how the cofactor formula comes about:

Take the matrix that contains  as the only entry in it’s first row as an example. If we cross out the row and the column that contain (i.e., row 1 and column 2), we’re left with a 2 x 2 matrix whose determinant is the minor of . If we multiply this minor by and put a minus sign in front of it (because that’s what the formula says to do), then you’ve got the -containing term that contributes to .
as the only entry in it’s first row as an example. If we cross out the row and the column that contain (i.e., row 1 and column 2), we’re left with a 2 x 2 matrix whose determinant is the minor of . If we multiply this minor by and put a minus sign in front of it (because that’s what the formula says to do), then you’ve got the -containing term that contributes to .
And if we apply the linearity properties of the determinant (i.e., rules 3a and 3b) to the matrix that contains as the only entry in it’s first row, we will obtain the same result. To see this, click on the link that follows:
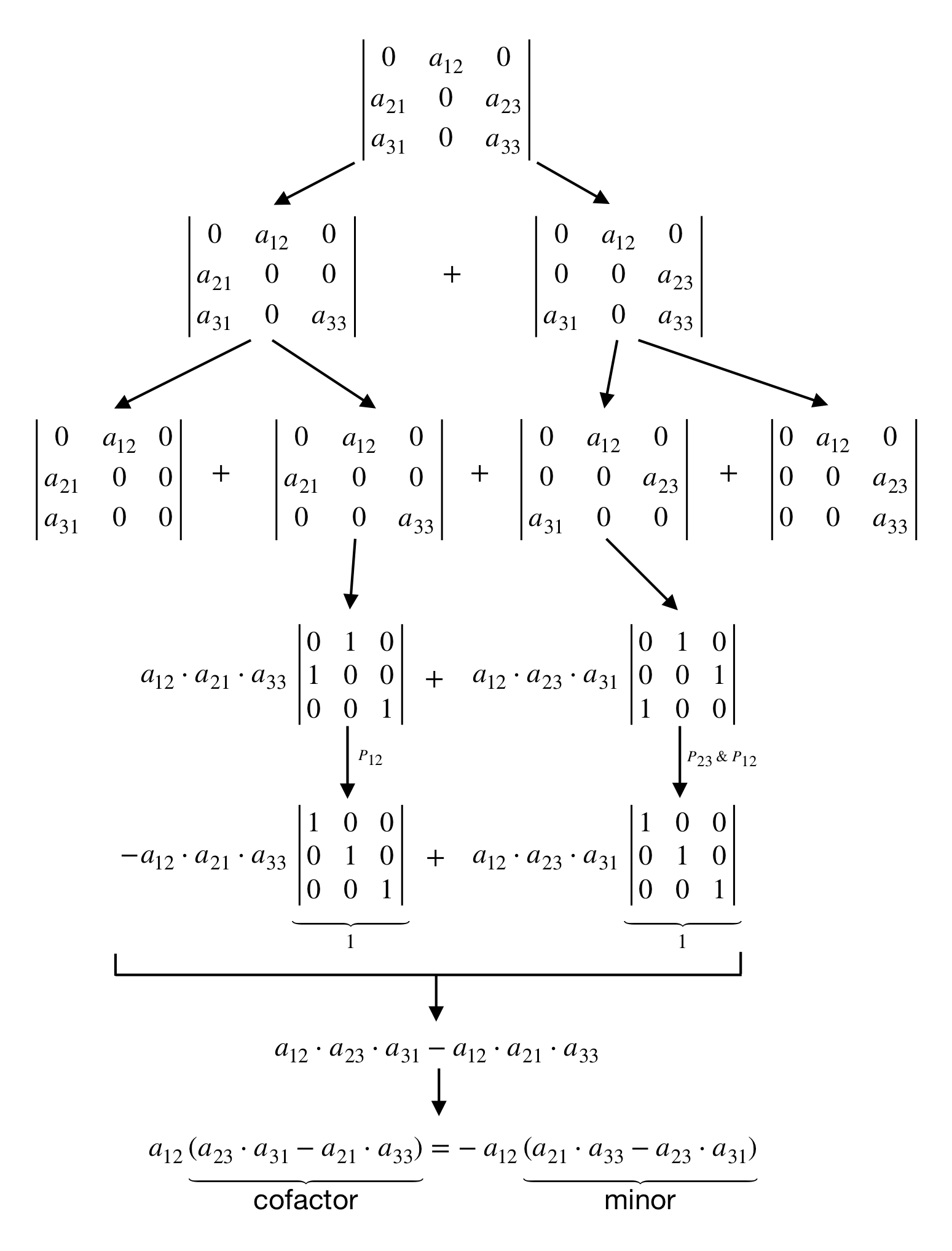
A proof of the general cofactor formula for the determinant, taken from the link from Purdue University listed above, is as follows:
For some matrix , we’ve seen that one of the ways to calculate is the big formula. We’ve also seen that we can factor out terms and the resulting rearranged expression will be equivalent to the original expression from which it came. In the example shown above, we factored out entries from the first row of the matrix. However, there’s no reason why we couldn’t factor out entries from any other row. Therefore, a general expression for such a factored expression for any row is

where the coefficients  contains no elements from row or column . In short, the coefficients are terms like
contains no elements from row or column . In short, the coefficients are terms like  noted in the example above. What we need to prove is that
noted in the example above. What we need to prove is that

is the cofactor of some matrix element .
Consider first the element  . From the big formula, the terms of that contain are given by
. From the big formula, the terms of that contain are given by

Thus,

However, this summation is just the minor of (which we’ve previously called  . From the cofactor formula, the first term in that formula has a positive sign. Thus,
. From the cofactor formula, the first term in that formula has a positive sign. Thus,  , and we have shown that the coefficient of in is , indeed, the cofactor
, and we have shown that the coefficient of in is , indeed, the cofactor  .
.
Now we need to do the same for any element in . To do this, consider the generic element . By successively interchanging adjacent rows and columns of , we can move to the  position without altering the relative position of the other rows and columnsmj. This creates a new matrix that we’ll call
position without altering the relative position of the other rows and columnsmj. This creates a new matrix that we’ll call  . Obtaining from requires -1 row exchanges and -1 column exchanges. Therefore, the total number of exchanges required to obtain from is
. Obtaining from requires -1 row exchanges and -1 column exchanges. Therefore, the total number of exchanges required to obtain from is  . Consequently,
. Consequently,

 and if we make an odd number of exchanges,
and if we make an odd number of exchanges,  . Since the total number of row or column exchanges is
. Since the total number of row or column exchanges is Now for the key argument:
- After all the row/column exchanges, the coefficient of in must be
 times the coefficient of in
times the coefficient of in 
- But occurs in the position of . So, as we have previously shown, it coefficient in is
 .
. - Since the relative positions of the remaining rows have not changed, it follows that

- Therefore, the coefficient of in is .
- Consequently, the coefficient of in is

This argument can be expressed mathematically as follows:

We can apply the above argument to elements  thus establishing the cofactor expansion along any row. The result for expansion along a column follows directly since
thus establishing the cofactor expansion along any row. The result for expansion along a column follows directly since
An example that illustrates the veracity of this proof comes from examining the element from the 3 x 3 matrix that we’ve working with before. Click on the button below to see this proof.

In the future, perhaps I will provide an example here, on this page, of calculating an n x n matrix using the cofactor expansion. However, for now, in the interest of time, I will simply provide a link to a video from Khan Academy that provides such an example. The video includes calculation of the determinant of a 4 x 4 matrix at about the 10 minute make. Here is the link:
Just a final word regarding the calculation of the determinant. When evaluating a determinant, it is generally most efficient to perform row/column operations (multiplication/addition and exchanges) until all but one (or few) of the terms in a row/column are zero, then apply the cofactor formula. In this way, since most of the terms are zero, only one or a few terms actually need to be evaluated.
Geometric interpretation of the determinant
Like matrix multiplication, looking at determinants from the point of view of linear transformations provides a geometric interpretation that further our understanding. In short, the determinant works as a scaling factor.
Recall that 1) a matrix creates a linear transformation that changes the length of basis vectors (which, for example in 2D, we called and ) and 2) the length of basis vectors determines the size of units that determine area in 2D, and unit boxes that determine volume in 3D. Therefore, matrices determine the size of units of area and volume in 2D and 3D, respectively.
Consider the 2D case. In the run-of-the-mill Cartesian coordinate system that we’re most familiar with, and  . Next extend a perpendicular line in the
. Next extend a perpendicular line in the  from the tip of and a perpendicular line in the
from the tip of and a perpendicular line in the  direction from . They intersect at the point
direction from . They intersect at the point  to make a polygon (in this case, a square) the basic unit of area in the Cartesian coordinate system. The matrix that creates this situation is
to make a polygon (in this case, a square) the basic unit of area in the Cartesian coordinate system. The matrix that creates this situation is  . A 2 x 2 polygon in this coordinate system, then, has an area of 4 square units (of whatever unit of length we may be using). This is depicted in the following diagram:
. A 2 x 2 polygon in this coordinate system, then, has an area of 4 square units (of whatever unit of length we may be using). This is depicted in the following diagram:
Now consider what happens if we use the matrix  to create a linear transformation. This matrix changes from
to create a linear transformation. This matrix changes from  to
to  and from
and from  to
to  , forming a new coordinate system. If we perform an operation similar to what we did in the Cartesian coordinate situation (project a vector parallel to from the end of ; project a vector parallel to from the end of ), we get a polygon that represents 1 unit of area in the new coordinate system. This is depicted in the following diagram. Also depicted is a 2 x 2 polygon (in this case, a parallelogram) in this new coordinate system.
, forming a new coordinate system. If we perform an operation similar to what we did in the Cartesian coordinate situation (project a vector parallel to from the end of ; project a vector parallel to from the end of ), we get a polygon that represents 1 unit of area in the new coordinate system. This is depicted in the following diagram. Also depicted is a 2 x 2 polygon (in this case, a parallelogram) in this new coordinate system.
Note that the parallelogram that represents the unit of area in the new coordinate system looks bigger than that in the Cartesian coordinate system. How much bigger? Well, we can actually derive a formula for this unit area. We’ll derive the general formula first, then determine what the unit area is in the above specific case.

Our goal is to find the area of the green parallelogram depicted above. To accomplish this, we do the following:
- Drop a perpendicular from the tip of to ; call it
 .
. - Draw a vector along from the origin to the point where intersects ; call it
 (for projection; is the projection of onto ).
(for projection; is the projection of onto ). - Since is on , we can express as a multiple of ,
 where is some constant (from the above diagram, it looks like it’s a fraction).
where is some constant (from the above diagram, it looks like it’s a fraction). - Note that
 , and based on what we just said,
, and based on what we just said,  .
. - Since is perpendicular to , the dot product

Now we need to do some algebra:

So,

Now we’re ready to find the area of the green parallelogram.
- The area of that parallelogram, , equals its base times its height:
 .
. - The base, , equals the length of
 ;
;  .
. - The height,
 ; It is unknown but can be found by the Pythagorean theorem:
; It is unknown but can be found by the Pythagorean theorem:
![\begin{array}{rcl}\lvert\hat{j}\rvert^2&=&\lvert\hat{h}\rvert^2 + \lvert\hat{p}\rvert^2\\ \lvert H \rvert^2&=&\lvert\hat{j}\rvert^2 - \lvert\hat{p}\rvert^2 \\ &=& \hat{j} \cdot \hat{j} - \lvert (\frac{\hat{i} \cdot \hat{j}}{\hat{i} \cdot \hat{i}})\hat{i} \rvert^2 \\ &=& \hat{j} \cdot \hat{j} - \left[\frac{\hat{i} \cdot \hat{j}}{\hat{i} \cdot \hat{i}}\hat{i} \cdot \frac{\hat{i} \cdot \hat{j}}{\hat{i} \cdot \hat{i}}\hat{i}\right] \\ &=& \hat{j} \cdot \hat{j} - \left[\frac{(\hat{i} \cdot \hat{j})(\hat{i} \cdot \hat{j})}{(\hat{i} \cdot \hat{i})(\hat{i} \cdot \hat{i})} \hat{i} \cdot \hat{i}\right] \\ &=& \hat{j} \cdot \hat{j} - \frac{(\hat{i} \cdot \hat{j})^2}{\hat{i} \cdot \hat{i}} \end{array}](https://www.samartigliere.com/wp-content/ql-cache/quicklatex.com-536588cf20a840f1df21bc01c1e42a5c_l3.png "Rendered by QuickLaTeX.com")
We said that . That means that  . Since
. Since  ,
,  . That gives us
. That gives us
![\begin{array}{rcl}A^2&=&\hat{i} \cdot \hat{i}\left[ \hat{j} \cdot \hat{j} - \frac{(\hat{i} \cdot \hat{j})^2}{\hat{i} \cdot \hat{i}} \right] \\ &=& (\hat{i} \cdot \hat{i})(\hat{j} \cdot \hat{j}) - (\hat{i} \cdot \hat{j})^2 \end{array}](https://www.samartigliere.com/wp-content/ql-cache/quicklatex.com-681f5578baa9f7bc775b77c00a8b03c8_l3.png "Rendered by QuickLaTeX.com")
Next, recall that it’s matrices that bring about linear transformations and specify and . Let’s consider the generic 2 x 2 matrix  . This matrix makes
. This matrix makes  and
and  .
.
Let’s substitute these values into the equation above:

That means that

But  is the determinant of the matrix . Therefore,
is the determinant of the matrix . Therefore,
The area of the parallelogram formed from the basis vectors specified by a 2 x 2 matrix is given by the determinant of that matrix.


Just as the basis vectors specified by a 2 x 2 matrix can be projected to form a parollelogram, the basis vectors specified by a 3 x 3 matrix can be projected to form a parallelepiped. And by similar arguments to those described for the 2 x 2 matrix, the determinant of a 3 x 3 matrix is the volume of the parallelepiped it forms.
A generic proof that the determinant of a matrix is the “volume” (or analog of volume) of a “parallelepiped” (or, more generally, geometric object) is taken from Strang’s textbook and the following link:
https://textbooks.math.gatech.edu/ila/determinants-volumes.html
Let’s start by defining the generic version of a parallelepiped. The parallelepiped determined by vectors  in
in  is the subset
is the subset
(1) 
In other words, a parallelepiped is the set of all linear combinations of vectors with coefficients from 0 through 1. So the length of the vectors we’re adding together are all  times (i.e., they are a fraction of) the
times (i.e., they are a fraction of) the  vectors that they are multiplying. This puts a limit on the length of the vectors that can be added together. If we let the tip of each of these linear combinations be represented by a point, these points will all be confined to locations on or within the parallelepiped specified by the vectors we are considering.
vectors that they are multiplying. This puts a limit on the length of the vectors that can be added together. If we let the tip of each of these linear combinations be represented by a point, these points will all be confined to locations on or within the parallelepiped specified by the vectors we are considering.
For example, take a parallelogram specified by the vectors  and
and  :
:

If we add to every point along , we get the upper margin of the parallelogram. If we add to , we get the right-hand margin. If we multiply each of an infinite number of coefficients, times , we get all of the points along the left-hand margin. And if we multiply an infinite number of coefficients, times , we get all of the points along the bottom margin of the parallelogram. If we create points from all of the other linear combinations we can make from coefficients times and , we get the inside of the parallelogram.
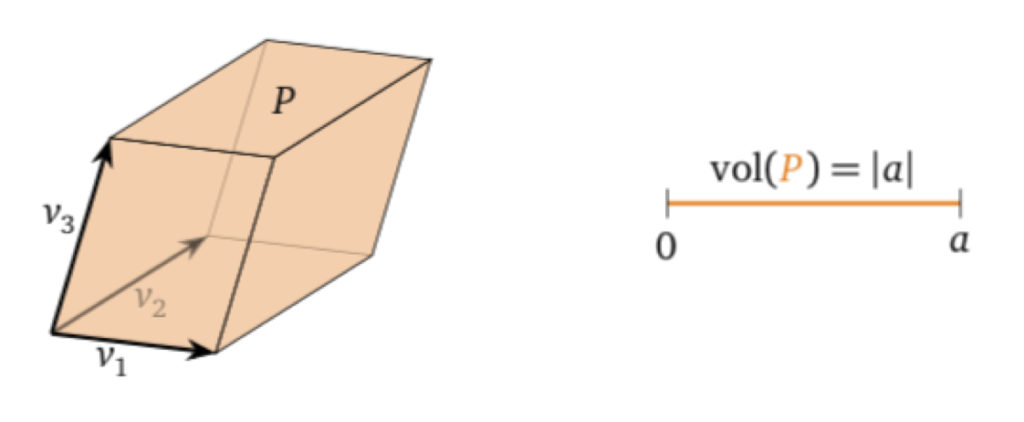
By the above argument, we can see how 3 vectors can be associated with a 3D parallelepiped (on the left in the above diagram). On the other hand, a single vector is associated with a “1D parallelepiped,” better known as a line, and its volume-analogue is its length (as shown in the figure on the right). Similar arguments can also be applied larger numbers of vectors creating higher dimensional objects (although such objects are difficult to visualize and diagram).
From this, the question arises: when does a parallelepiped formed in the way described above have zero volume? Answer: when it is squashed to a lower dimension (e.g., two vectors that form a line, three vectors that form a plane). And when does this occur? When one or more of the vectors are linearly dependent (i.e., are linear combinations of other vectors in the set). This is shown in the diagram below:
Now if we have a matrix, , with two rows that are multiples of each other, if we multiply one of these rows by the correct factor, and subtract it from its linearly dependent counterpart, we create a new matrix, , with a row of zeros. But by determinant property 6, if a matrix has a row of zeros, then its determinant is zero. Furthermore, since we created by subtracting a multiple of one row from another, by determinant property 5,  . And since
. And since  , also equals zero. This leads us to the conclusion that, if a matrix has two (or more) rows that are linear dependent (i.e., are linear combinations of each other), then its determinant is zero. And because determinant property 10 says that , the same applies if two or more columns of a matrix are linearly dependent.
, also equals zero. This leads us to the conclusion that, if a matrix has two (or more) rows that are linear dependent (i.e., are linear combinations of each other), then its determinant is zero. And because determinant property 10 says that , the same applies if two or more columns of a matrix are linearly dependent.
So here’s the punchline:
- A parallelepiped formed from a matrix with columns has a volume of zero if and only if it has linearly dependent rows or columns.
- If a matrix has linearly dependent rows or columns, then its determinant is zero.
Therefore, a parallelepiped formed from the columns of a matrix, , has zero volume if and only if the determinant of that matrix is zero.
But this is only the beginning of the story. It turns out that the volume of such a parallelepiped is always a determinant. Specifically,
Let be vectors in , let be the parallelepiped determined by these vectors, and let be the matrix with rows . Then the absolute value of the determinant of is the volume of :
![\[ \lvert \det{A} \rvert = \text{vol}(P) \]](https://www.samartigliere.com/wp-content/ql-cache/quicklatex.com-36bd3cac93687b770dad7f8e7bbaa41f_l3.png "Rendered by QuickLaTeX.com")
To prove this, we’ll prove that  follows properties 1-3 of the determinant.
follows properties 1-3 of the determinant.
Property 1: The determinant of the identity matrix,  , is equal to 1.
, is equal to 1.
- If the number of dimensions is one, and the matrix
 , then its “volume-analogue” (= its length) equals 1 and so does .
, then its “volume-analogue” (= its length) equals 1 and so does . - If we’re dealing with a 2-dimensional space, the area of such a space is the unit square which equals 1. In this case, the matrix would equal and , like the area, would also be 1.
- If we’re dealing with a 3D space, the volume would be the unit cube which has volume 1. In this case, the matrix would equal
 and , like the area, would also be 1.
and , like the area, would also be 1. - If
 , then the volume-analogue is still 1 unit. The matrix associated with this space is
, then the volume-analogue is still 1 unit. The matrix associated with this space is  . The determinant of that matrix, like any version of the identity matrix, is still 1.
. The determinant of that matrix, like any version of the identity matrix, is still 1.
Property 2: The determinant changes sign when two rows are exchanged.
However, a corollary to this property is that, although the sign of the determinant changes, its absolute value remains unchanged. When we swap rows, we just change the order of the rows in the matrix. When we make, for example, a parallelogram out of those rows, we change the orientation of the parallelogram. However, the angle between the vectors and the vector magnitudes remain the same. Therefore, the area of the new parallelogram remains the same. The same argument applies to other parallelepipeds as well. The following is an example of this in two dimensions:

- The area of this parallelogram equals base times height:
 .
. - equals the length of
 ,
,  .
.  .
. .
.

- So


- The area of the above parallelogram equals base times height: .
- equals the length of , .
- .
 .
.- So
So we can see that the areas of these two parallelograms-formed from matrices whose rows have been swapped-are equal. And since, when we apply row swaps to higher dimensional matrices, we make them one at a time. Geometrically, that correlates with swapping vectors on a single “face” of the higher dimensional object. And that “face” is just a 2D parallelogram. So the argument we just went through for parallelograms applies exactly to the row swaps we make in the higher dimensional object. When we make such a row swap in a higher dimensional geometric object, the area of the object, after a swap, remains the same.
You may have noticed that the determinants of the row-swapped matrices that were used to construct the two parallelograms above actually have opposites signs:

However, this doesn’t contradict the theorem we are trying to prove,

since

However, there is a geometric analogue for negative area. It involves application of the so-called right hand rule:
- Put your hand on .
- Curl your fingers toward
 and stick your thumb up.
and stick your thumb up. - If your thumb points out of the paper (or screen) toward you, it represents positive area.
- If your thumb points into the paper (or screen) away from you, it represents negative area.
- For 3D volumes
- Position your hand on and as in the 2D case
- If the component of the third vector that determines the volume points in the same direction as your thumb, the volume is positive.
- If the component of the third vector that determines the volume points in the opposite direction of your thumb, the volume is negative.
- Position your hand on
- Visualization is difficult when
 .
.
Property 3a: If a row from a matrix, , is added to one of the rows of a matrix, , that is the same as except for the row to which the row from is added, the determinant of the resulting matrix, , is the sum of the determinant of plus the determinant of :

The geometric analogue to this is:

To illustrate this, we’ll expand the example we’ve been using, using numbers rather than variables to make visualization easier. Specifically,
 is the parallelogram constructed from
is the parallelogram constructed from 
 is the parallelogram constructed from
is the parallelogram constructed from 
 is the parallelogram constructed when row 1 of is added to row 1 of :
is the parallelogram constructed when row 1 of is added to row 1 of :



So,

The areas of the parallelograms demonstrate the same addition property that the determinant does:
![\begin{array}{rcl} \det{P_{A^\prime}}&=&\det{P_{A}}+\det{P_{B}}\\ \begin{vmatrix}4&2\\1&2\end{vmatrix}&=&\begin{vmatrix}3&1\\1&2\end{vmatrix}+\begin{vmatrix}1&1\\1&2\end{vmatrix}\\ (4)(2)-(1)(2)&=&\left[(3)(2)-(1)(1)\right]+\left[(1)(2)-(1)(1)\right]\\ (8-2)&=&(6-1)+(2-1)\\ 6&=&5+1 \end{array}](https://www.samartigliere.com/wp-content/ql-cache/quicklatex.com-a801edab5819885030c17cbd2d2f18f5_l3.png "Rendered by QuickLaTeX.com")
And as we discussed above, when we add a row to a matrix that determines a parallelepiped in a higher dimension, we are performing this operation on one “face” (or side). Of course, one face or side is a parallelogram, and we just proved that the area of a parallelogram follows determinant property 3a, so the “volume” of the parallelepiped must also follow determinant property 3a.
Property 3b: If we multiply a row of a matrix by some constant, then the determinant of the new matrix so created equals the determinant of the original matrix times the constant.
In equation format:

What we want to prove is that, if we
- make a parallelogram,
 from matrix
from matrix - multiply the second row of by a constant, to get a new matrix,

- make a parallelogram from
Then the area of ,  , equals times the area of (
, equals times the area of ( ):
):

For ease of visualization, let’s prove this using numbers instead of variables, like we did in the last case. Specifically, we’ll multiply a row of the matrix  by
by  , form a parallelogram from that matrix and see what happens. Since we can multiply any row of a matrix and get the same result, let’s multiply the second row of by 2. Why the second row? Simply so the resulting matrix fits on our page.
, form a parallelogram from that matrix and see what happens. Since we can multiply any row of a matrix and get the same result, let’s multiply the second row of by 2. Why the second row? Simply so the resulting matrix fits on our page.
When we do this, we get:

Next, we make a parallelogram, like we have been doing, from the columns of  . We have
. We have  and
and  :
:


We set out to prove that . From our previous calculations, . From the calculation we just performed,
. From the calculation we just performed,  . Then
. Then

The areas of the parallelograms demonstrate the same multiplication property that the determinant does:
![\begin{array}{rcl}\det{A^\prime}&=&2\det{A}\\ \begin{vmatrix}3&1\\2&4\end{vmatrix}&=&2\begin{vmatrix}3&1\\1&2\end{vmatrix}\\ (3)(4)-(2)(1)&=&2\left[ (3)(2)-(1)(1) \right]\\ 12-2&=&2(6-1)\\ 10&=&2\times 5 \end{array}](https://www.samartigliere.com/wp-content/ql-cache/quicklatex.com-c7df5f8988b108ffbd0587475b07e0cf_l3.png "Rendered by QuickLaTeX.com")
This is what we sought to prove.
And similar to what we’ve argued before, when we multiply a row to a matrix that determines a parallelepiped in a higher dimension, we are performing this operation on one “face” (or side). Of course, one face or side is a parallelogram, and we just proved that the area of a parallelogram follows determinant property 3b, so the “volume” of parallelepipeds, in general, must also follow determinant property 3b.
Uses of the determinant
There are several uses of the determinant. Here are three of the most important.
Finding the inverse of a matrix
The first use of the determinant that we will discuss is finding the inverse of a matrix. The formula used to do this is:
 where
where
is the inverse of a matrix,
is the determinant of
 is the transverse of a matrix of cofactors for each term in
is the transverse of a matrix of cofactors for each term in
Following the arguments laid out it Strang’s textbook, we will derive this formula in two steps. The first step involves describing and deriving Cramer’s rule.
Cramer’s rule
Cramer’s rule, ultimately, is a method of solving the matrix equation , albeit a tedious one. However, it’s great for seeing where the formula for finding the inverse of a matrix using the determinant comes from.

Make column 1 of the identity matrix in the above equation the vector,  that we want to find. Multiply that resulting matrix with matrix . We get a matrix that is the same as except that its first column is the vector (i.e., the “answer” to the equation that we want to solve):
that we want to find. Multiply that resulting matrix with matrix . We get a matrix that is the same as except that its first column is the vector (i.e., the “answer” to the equation that we want to solve):

Now take the determinant of the three matrices. We have:

If you’re wondering why  , click .
, click .

To find , we put into the second column of the identity matrix, multiply, then take the determinant of the three matrices:


To find , we put into the third column of the identity matrix, multiply, then take the determinant of the three matrices:


Thus,

Proof
So we’ve solved our equation . Since the columns of a matrix are, themselves, vectors, we could perform matrix multiplication by applying Cramer’s rule column by column. The specific equation I want want to solve with this method is for the case of a generic 2 x 2 matrix:
 where
where



We can break this matrix multiplication into two equations:

Solving the first equation:


and


Solving the second equation:


and


So we’ve got

That means,

Factor out  :
:

Thus, we’ve found a formula for the inverse of a 2 x 2 matrix. However, an important observation stems from this exercise, an observation that leads to a key generalization:
In applying Cramer’s rule, because each right-hand side matrix  we create contains a row of the identity matrix, the determinant of each matrix is a cofactor.
we create contains a row of the identity matrix, the determinant of each matrix is a cofactor.
We can see this by examining the solution to for a 3 x 3 matrix. We just want to illustrate the principle so we’ll only evaluate the determinants  that result from solutions for the first row of :
that result from solutions for the first row of :






And just as in the 2 x 2 and 3 x 3 cases, when solving for higher dimensional cases
The entry of is the cofactor  (not ) divided by .
(not ) divided by .
Formula for 
As indicated in the above formula, the terms can be put into a matrix, :

Remember, terms are associated with a  or
or  sign according to the formula
sign according to the formula  where is the so-called minor of the entry of the matrix , made by “crossing out” the -th row and -th column of then taking the determinant of the remaining terms.
where is the so-called minor of the entry of the matrix , made by “crossing out” the -th row and -th column of then taking the determinant of the remaining terms.
Another proof of the formula for the inverse of a matrix using the determinant goes as follows:
Let’s start by multiplying  and see what we get. Let’s take a 3 x 3 example:
and see what we get. Let’s take a 3 x 3 example:

Let’s start by multiplying (row 1 of )(column 1 of ):

Likewise,

and

So far, we have,

It turns out that the diagonal elements of the right-hand matrix are all . What about the non-diagonal elements? Let’s consider the first row/second column of the matrix that makes up the right-hand side of the equation:
 Why is it 0? Because this expression is cofactor expansion of a matrix in which the first row of is copied and replaces the second row of A. Since such a matrix (we’ll call it
Why is it 0? Because this expression is cofactor expansion of a matrix in which the first row of is copied and replaces the second row of A. Since such a matrix (we’ll call it  ) has two rows that are the same, it’s determinant is zero. Therefore, the expression evaluates to zero. Here it is, spelled out in detail:
) has two rows that are the same, it’s determinant is zero. Therefore, the expression evaluates to zero. Here it is, spelled out in detail:

Compare this with the determinant of  :
:

They are the same! But has two rows that are identical. Therefore, by property 4 of the determinant,  . That means that the entry in the 1,2 (off-diagonal) position of the matrix product of equals 0.
. That means that the entry in the 1,2 (off-diagonal) position of the matrix product of equals 0.
Let’s check another example. Let’s calculate the 3,2 entry in the matrix product of (i.e., the third row/second column of the right-hand matrix in the equation ![AC^T=\left[?\right]](https://www.samartigliere.com/wp-content/ql-cache/quicklatex.com-abe27231d12c20de6336b7c891551062_l3.png "Rendered by QuickLaTeX.com") ). The expression we get for this entry by multiplying the third row of times the second column of is:
). The expression we get for this entry by multiplying the third row of times the second column of is:

But this is the determinant of a matrix in which the third row of has been copied and pasted in place of the second row of . We’ll call this matrix
 .
.
Expanding the third row of this matrix by its cofactors, we find that,

Alas, similar to our first example, multiplication of the third row of by the second column of is the same as  But
But  has two rows that are identical. Therefore, by property 4 of the determinant,
has two rows that are identical. Therefore, by property 4 of the determinant,  . That means that the entry in the 3,2 (off-diagonal) position of the matrix product of equals 0.
. That means that the entry in the 3,2 (off-diagonal) position of the matrix product of equals 0.
It turns out that all of the diagonal elements of the matrix product of equal 0. This is because, in general, if  (i.e., our product is producing diagonal elements), the expression formed by multiplying the th row of by the th column of is the determinant of a matrix where the th row of is copied and replaces the th row of . That matrix always has two identical rows. Therefore, the determinant of that matrix is 0. And since our expression equals that determinant, the value of our expression is always 0.
(i.e., our product is producing diagonal elements), the expression formed by multiplying the th row of by the th column of is the determinant of a matrix where the th row of is copied and replaces the th row of . That matrix always has two identical rows. Therefore, the determinant of that matrix is 0. And since our expression equals that determinant, the value of our expression is always 0.
So now we’ve shown that

Factor out from the right-hand side. We are left with

So the relationship we wind up with is  . Of course, if this is true for 2 x 2 and 3 x 3 matrices, we could, with some additional work, show that it is also true for any n x n matrix. From here, the proof ending in a generic formula for the inverse of a matrix using the determinant goes like this:
. Of course, if this is true for 2 x 2 and 3 x 3 matrices, we could, with some additional work, show that it is also true for any n x n matrix. From here, the proof ending in a generic formula for the inverse of a matrix using the determinant goes like this:

Thus, the general formula for the inverse of a matrix is:
![\[ \mathbf{A^{-1}=\frac{1}{\det{A}}C^T} \]](https://www.samartigliere.com/wp-content/ql-cache/quicklatex.com-46dd463a072420aa47b5b560a1127908_l3.png "Rendered by QuickLaTeX.com")
Determining existence of a unique solution
The existence or nonexistence of a determinant for a matrix can tell us whether or not, respectively, there is a unique solution to the equation . This is because, from all that we’ve discussed so far, we can deduce the following:
- If a matrix has a row of zeros or one or more rows that is(are) linear combination(s) of each other, then that matrix is singular.
- If a matrix is singular, then it does not have a unique solution to the equation . Instead it has no solution or an infinite number of solutions.
Therefore, if a matrix has a determinant of zeros, it is singular and has no solution or an infinite number of solutions to the equation .
In contrast,
- If all of the rows of a matrix are linearly independent (i.e., it has full rank, or said another way, it has no row of zeros or one or more rows that is(are) linear combination(s) of each other), then that matrix is nonsingular.
- If a matrix is nonsingular, then it has a unique solution to the equation .
Therefore, if a matrix has a nonzero determinant, it is nonsingular and has a single unique solution to the equation .
Finding eigenvalues
This is an important application of the determinant to which we’ll devote an entire section.
Eigenvalues and Eigenvectors
Consider the generic matrix-vector multiplication equation . Looking at this problem geometrically, the product of this equation, , is usually a vector that points in a different direction than . However, occasionally, does point in the same direction as (i.e., is a scalar multiple of ). When this occurs, is called an eigenvector of and the scalar that multiplies it is called an eigenvalue.
Definition
In terms of equations, if is an  matrix, then
matrix, then
- An eigenvalue of is a number,
 , such that
, such that  .
. - An eigenvector of is a nonzero vector, such that for some number .
Calculating eigenvalues and eigenvectors
Start with the equation
. Subtract  from both sides. That leaves:
from both sides. That leaves: . Factor out from the left side. That gives us:
. Factor out from the left side. That gives us:
- Since we’re looking for eigenvectors, has to be nonzero.
- If is nonzero, that means that the matrix
 is singular.
is singular. - If is singular, then that means that

- Solving
 is how the eigenvalues,
is how the eigenvalues,  , are found.
, are found. - Once the eigenvalues,
 , are found, the equation is solved for each eigenvalue to find the corresponding eigenvector,
, are found, the equation is solved for each eigenvalue to find the corresponding eigenvector,  .
.
Note that we could have subtracted
from both sides of before factoring out . This would leave us with  . This is equivalent to . Thus, we could use either to find the eigenvalues of . It turns out that is positive in the algebraic equations needed to find these eigenvalues when is used. Thus, I generally prefer to work with this form.
. This is equivalent to . Thus, we could use either to find the eigenvalues of . It turns out that is positive in the algebraic equations needed to find these eigenvalues when is used. Thus, I generally prefer to work with this form.Some examples, taken from Khan Academy, will help to illustrate how all this works.
Example 1 (from https://www.khanacademy.org/math/linear-algebra/alternate-bases/eigen-everything/v/linear-algebra-example-solving-for-the-eigenvalues-of-a-2×2-matrix)
a. Find the eigenvalues of the matrix
 . for nonzero
. for nonzero  iff
iff  .
.

Therefore,
 and
and 
b. Now we need to find the corresponding eigenvectors. To do this, we need to substitute
 then
then  into
into Let’s start with
.
This implies that

There are actually an infinite number of vectors that solve this equation. This infinite number of vectors forms a vector space and is given the special name of an eigenspace. We’ll represent that here by the letter “E”.
So the eigenspace that corresponds to the eigenvalue
,  . (
. ( means that is an element of the real numbers i.e., is some real number.) In other words, there are an infinite number of eigenvectors that are associated with , all linear combinations of
means that is an element of the real numbers i.e., is some real number.) In other words, there are an infinite number of eigenvectors that are associated with , all linear combinations of 
Now for the eigenvectors associated with
.
This implies that

So the eigenspace that corresponds to the eigenvalue
,  . In other words, there are an infinite number of eigenvectors that are associated with , all linear combinations of
. In other words, there are an infinite number of eigenvectors that are associated with , all linear combinations of 
Example 2 (from Khan Academy https://www.khanacademy.org/math/linear-algebra/alternate-bases/eigen-everything/v/linear-algebra-eigenvalues-of-a-3×3-matrix)
a. Find the eigenvalues of the matrix
 . for nonzero iff .
. for nonzero iff .![\begin{array}{rcl} \begin{vmatrix}\lambda&0&0\\0&\lambda&0\\0&0&\lambda\end{vmatrix}-\begin{vmatrix}-1&\,\,\,\,\,2&\,\,\,\,\,2\\\,\,\,\,\,2&\,\,\,\,\,2&-1\\\,\,\,\,\,2&-1&\,\,\,\,\,2\end{vmatrix}&=&0\\ \begin{vmatrix}\lambda+1&\,\,\,\,\,2&\,\,\,\,\,2\\ \,\,\,\,\,2&\,\,\,\,\,\lambda-2&-1\\ \,\,\,\,\,2&-1&\,\,\,\,\,\lambda-2\end{vmatrix}&=&0\\ (\lambda+1)\begin{vmatrix}\lambda-2&1\\1&\lambda-2\end{vmatrix}-(-2)\begin{vmatrix}-2&1\\-2&\lambda-2\end{vmatrix}+(-2)\begin{vmatrix}-2&\lambda-2\\-2&1\end{vmatrix}&=&0\\ (\lambda+1)\left[ (\lambda-2)^2 - 1 \right] - (-2)\left[ -2(\lambda-2) - (-2)1 \right] + (-2)\left[ (-2)1 - (-2)(\lambda-2) \right]&=&0\\ (\lambda^3-4\lambda^2+3\lambda+3)+(-4\lambda+12)+(-4\lambda+12)&=&0\\ \lambda^3-3\lambda^2-9\lambda+27&=&0 \end{array}](https://www.samartigliere.com/wp-content/ql-cache/quicklatex.com-193f3df98b94e5112c7f73e50e704c92_l3.png "Rendered by QuickLaTeX.com")
 is called a characteristic polynomial. As seen before, to find the eigenvalues, we have to set the character polynomial equal to zero and solve for . To do this, we have to factor the characteristic polynomial. To factor this particular polynomial requires polynomial long division. We take a guess regarding what one of it’s factors might be by playing with combinations that might give us the constant term
is called a characteristic polynomial. As seen before, to find the eigenvalues, we have to set the character polynomial equal to zero and solve for . To do this, we have to factor the characteristic polynomial. To factor this particular polynomial requires polynomial long division. We take a guess regarding what one of it’s factors might be by playing with combinations that might give us the constant term  . A factor involving the number 3 is a good guess. Let’s try
. A factor involving the number 3 is a good guess. Let’s try  . Actually, the LaTex add-on that’s used to render polynomial long division doesn’t seem to recognize . So temporarily, let
. Actually, the LaTex add-on that’s used to render polynomial long division doesn’t seem to recognize . So temporarily, let  . We have:
. We have:
 . Therefore, we are left with:
. Therefore, we are left with:
So our eigenvalues are
 ,
,  and
and  . Since and are redundant, we only have to worry about two eigenvalues: and
. Since and are redundant, we only have to worry about two eigenvalues: and  .
.b. Eigenvectors (taken from Khan Academy, https://www.khanacademy.org/math/linear-algebra/alternate-bases/eigen-everything/v/linear-algebra-eigenvectors-and-eigenspaces-for-a-3×3-matrix)
Let’s calculate the eigenvectors/eigenspace for
first. Essentially, what we’ll be doing is calculating the null space of the matrix 

Now perform some row operations on the matrix on the left side of the equation:
- Subtract row 2 from row 3 to get a row of zeros in row 3.
- Add
 row 1 from row 2 to get a row of zeros in row 2.
row 1 from row 2 to get a row of zeros in row 2.
After these operations, we have,

Divide row 1 by 2:

Now multiply out the matrix-vector combination above. The only useful equation that comes out of it is:

Set


Set


So the eigenspace for eigenvalue
(which consists of all of the eigenvectors associated with ) is:
Next let’s calculate the eigenspace associated with
.
Now we need to do some row operations. Start by dividing row 1 by
:
Add 2 times row 1 to row 3:

Add 2 times row 1 to row 2:

Add row 2 to row 3:

Divide row 2 by 3:

From that, we conclude that:

And

Set

So the eigenspace for eigenvalue
(which consists of all of the eigenvectors associated with ) is:
2 important theorems
Here are two theorems, that when proven, may be helpful.
The product of the eigenvalues of a matrix equals the determinant of the matrix
Proof
To find the eigenvalues for a matrix
, we need to solve the following equation:
where
 is the so-called characteristic polynomial. After factoring the characteristic polynomial, we wind up with something like this
is the so-called characteristic polynomial. After factoring the characteristic polynomial, we wind up with something like this
where
 are the eigenvalues of (i.e., compare the equation above with expression we got on the left side of the equation after we factored the characteristic polynomial in example 2 above:
are the eigenvalues of (i.e., compare the equation above with expression we got on the left side of the equation after we factored the characteristic polynomial in example 2 above: 
So

Recall also that

So

It turns out that
 . This may not be immediately obvious (at least it wasn’t to me). To see that this is so, click
. This may not be immediately obvious (at least it wasn’t to me). To see that this is so, click
So far, we’ve derived the following two equations:
And

That means that

Now divide both sides of this equation by
 . We get:
. We get:
Which is what we wanted to prove.
The sum of the eigenvalues of a matrix equals the trace of that matrix.
Proof
Consider the matrix
To find the eigenvalues of , we solve the equation:
, we solve the equation:

When we calculate the determinant on the lefthand side of the equation, we get the characteristic polynomial of the form:

This characteristic polynomial can ultimately be factored into the product of an entity called a zero, an entity of the form
 . It’s called a zero because, if you set this expression equal to zero and solve for , you get one of the solutions to the equation. In the case we’re considering, after factoring, the expression we get looks something like this:
. It’s called a zero because, if you set this expression equal to zero and solve for , you get one of the solutions to the equation. In the case we’re considering, after factoring, the expression we get looks something like this:
As shown above,
 are the eigenvalues of .
are the eigenvalues of .
There is a theorem in elementary algebra that says, if we have a polynomial like the one above, then the coefficient of the
 term –
term –  – is equal to the sum of the roots,
– is equal to the sum of the roots,  :
:
For proof of this, click here.
Now look back at the determinant

To calculate this determinant, we multiply each entry of a row,
(or column, but for this discussion, we’ll stick with rows, specifically the first row) with its cofactor, . The only way to get a term raised to a power as high as  from these multiplications is to have all of the diagonal elements of our matrix involved in the multiplications. Why? Because that is where all the
from these multiplications is to have all of the diagonal elements of our matrix involved in the multiplications. Why? Because that is where all the  lie.
lie.Here is an example that shows this:
![\begin{array}{rcl} \begin{vmatrix}\lambda-a_{11}&a_{12}&a_{13}\\ a_{21}&\lambda-a_{22}&a_{23}\\ a_{31}&a_{32}&\lambda-a_{33}\end{vmatrix}&=&0\\&\,&\\ \lambda-a_{11}\begin{vmatrix} \lambda-a_{22}&a_{23}\\ a_{32}&\lambda-a_{33} \end{vmatrix}-a_{12}\begin{vmatrix} a_{21}&a_{23}\\ a_{31}&\lambda-a_{33} \end{vmatrix}+a_{13}\begin{vmatrix} a_{21}&\lambda-a_{22}\\ a_{31}&a_{32} \end{vmatrix}&=&0\\&\,&\\ (\lambda-a_{11})\left[ (\lambda-a_{22})(\lambda-a_{33})-a_{23}a_{32} \right]+\dots&=&0\\&\,&\\ (\lambda-a_{11})\left[ (\lambda^2-a_{33}\lambda-a_{22}\lambda-a_{22}a_{32}-a_{23}a_{32} \right]+\dots&=&0\\&\,&\\ \begin{matrix}\underbrace{\lambda^3-a_{33}\lambda^2-a_{22}\lambda^2+\lambda(a_{22}a_{32}+a_{22}a_{33}-a_{23}a_{32})}}_{\text{from multiplication by }\lambda}+\\ \underbrace{-a_{11}\lambda^2-a_{11}(-a_{33}\lambda-a_{22}\lambda)-a_{11}(a_{22}a_{33}-a_{23}a_{32})}_{\text{from multiplication by }-a_{11}}+\\ \underbrace {\dots \dots \dots \dots \dots \dots}_{\text{things not pertinent to this discussion}}\end{matrix}&=&0\\&\,&\\ \lambda^3-a_{33}\lambda^2-a_{22}\lambda^2-a_{11}\lambda^2+\text{ things not pertinent to this discussion }&=&0\\&\,&\\ \lambda^3-(a_{11}+a_{22}+a_{33})\lambda^2+\text{ things not pertinent to this discussion }&=&0 \end{array}](https://www.samartigliere.com/wp-content/ql-cache/quicklatex.com-b293de3b643cd4fabfd48751dbd917aa_l3.png "Rendered by QuickLaTeX.com")
(To see
 expanded completely, click )
expanded completely, click )
So,
- The term in the above polynomial is the
 term.
term. - The coefficient of the term in the above polynomial is
 .
. - The eigenvalues of the matrix, , are . is the trace of .
Therefore, the sum of the eigenvalues of
equals the trace of .Here are a couple of comments regarding these two theorems which may seem obvious to the reader but which I found a bit confusing when I first learned about them:
First, it’s important to note that while the sum of the eigenvalues (the
) of a matrix, , equals the sum of the trace of that matrix , it is NOT TRUE that the eigenvalues equal the entries along the trace of . Rather, the individual eigenvalues of equal the roots of the characteristic polynomial (the  ). That is,
). That is, .
.Second, the constant term at the end of the characteristic polynomial equals the determinant. Here’s why:



Therefore,

That these theorems and comments regarding them are true can be verified by examining the examples of eigenvalue calculations provided earlier in this section.
Additional facts
Here are a few useful facts about eigenvalues/eigenvectors that won’t be demonstrated here but can be shown by doing out the calculations:
- Eigenvalues and eigenvectors can only be found for square matrices.
- Eigenvalues can be 0 but eigenvectors can never be the 0 vector.
- One of the eigenvalues of a singular matrix is always 0.
- When a matrix, , is squared, its eigenvectors stay the same but its eigenvalues are squared.
- Projection matrices have eigenvalues of 0 and 1.
- The reflection matrix,
 has eigenvalues 1 and -1.
has eigenvalues 1 and -1. - Eigenvalues can be complex numbers.
- The rotation matrix,
 , has eigenvalues of and
, has eigenvalues of and  .
. - Triangular matrices have their eigenvalues on their diagonal.
Diagonalizing a matrix
Derivation of formula
(Discussion taken from Strang pp. 298-303)
Let
be a matrix with  where
where
 are the eigenvalues of
are the eigenvalues of
 are the eigenvectors of
are the eigenvectors of Let
 be a matrix of the eigenvalues of :
be a matrix of the eigenvalues of :
Let
 be a matrix akin to the identity matrix but with the eigenvalues of along the diagonal, replacing the 1’s:
be a matrix akin to the identity matrix but with the eigenvalues of along the diagonal, replacing the 1’s:
Because

But

Therefore,

We can multiply the inverse of
–  – on the right side or left side of both sides of . When we do, we get:
– on the right side or left side of both sides of . When we do, we get:
and

Property
If an
 matrix, , has independent eigenvalues, then its eigenvectors will be linearly independent and will be diagonizable.
matrix, , has independent eigenvalues, then its eigenvectors will be linearly independent and will be diagonizable.Proof
Suppose
 .
.Multiply by
. We have .
.Multiply by
. We get
 and are different. Thus,
and are different. Thus,  is not zero.
is not zero.  is not zero because it’s an eigenvector. That must mean that
is not zero because it’s an eigenvector. That must mean that  .
.Next, multiply
by . We get
Subtract this from
. That gives us:
Similar to what we said above:
and are different. Thus,  is not zero.
is not zero.  is not zero because it’s an eigenvector. That must mean that
is not zero because it’s an eigenvector. That must mean that  .
.This proof can be extended to involve all of the eigenvectors associated with a matrix
. Suppose has eigenvectors. Assume  . Apply the algorithm we have been applying: 1) multiply by 2) multiply by
. Apply the algorithm we have been applying: 1) multiply by 2) multiply by  3) subtract. This removes
3) subtract. This removes  . Next, again, multiply by , multiply by
. Next, again, multiply by , multiply by  then subtract. This removes
then subtract. This removes  . Keep doing this until only is left:
. Keep doing this until only is left:
By the argument we’ve used multiple times before,
. We can repeat the same procedure for every  (where is an integer between and ). In each case, the result will be the same: will be equal to 0.
(where is an integer between and ). In each case, the result will be the same: will be equal to 0.But that means that

That is, the only linear combination of the eigenvectors of
(i.e., ) is the one where the coefficients of the are all zero. But this is the definition of linear independence.Thus, if the eigenvalues of
are independent, then its eigenvectors are linearly independent.Some matrices are not diagonalizable. In order for an
 matrix to be diagonalizable, it has to have independent eigenvalues and eigenvectors. What makes a matrix not diagonalizable is too few eigenvectors to “fill” the eigenvector matrix .
matrix to be diagonalizable, it has to have independent eigenvalues and eigenvectors. What makes a matrix not diagonalizable is too few eigenvectors to “fill” the eigenvector matrix .Uses
Powers of
The diagonalized form of a matrix can be used to calculate a matrix raised to a power,
 without performing matrix multiplication times. Here is why:
without performing matrix multiplication times. Here is why:


A continuation of this process will ultimately lead to:

 is relatively easy to calculate. All we have to do is raise each diagonal entry of to the
is relatively easy to calculate. All we have to do is raise each diagonal entry of to the  power – much easier than multiplying together times.
power – much easier than multiplying together times.Application of Powers of A
We want to prove and use:

 can be split into three steps:
can be split into three steps:- Write
 as a linear combination
as a linear combination  of the eigenvectors. Then
of the eigenvectors. Then  .
. - Multiply each eigenvector
 by
by  . Now we have
. Now we have  .
. - Add up pieces
 to find the solution
to find the solution  . This is
. This is  .
.
is such that


We can break this down step-by-step:
Step 1




Step 2
Step 3


But
Thus
And if we operate on
 with , we get
with , we get  :
: - Since we’re looking for eigenvectors,
 case:
case:

 . This example illustrates that, if
. This example illustrates that, if  .
. .
.



 . This example illustrates that, if
. This example illustrates that, if  .
.![\begin{array}{rcl} \begin{vmatrix}\lambda-a_{11}&a_{12}&a_{13}\\ a_{21}&\lambda-a_{22}&a_{23}\\ a_{31}&a_{32}&\lambda-a_{33}\end{vmatrix}&=&0\\&\,&\\ \lambda-a_{11}\begin{vmatrix} \lambda-a_{22}&a_{23}\\ a_{32}&\lambda-a_{33} \end{vmatrix}-a_{12}\begin{vmatrix} a_{21}&a_{23}\\ a_{31}&\lambda-a_{33} \end{vmatrix}+a_{13}\begin{vmatrix} a_{21}&\lambda-a_{22}\\ a_{31}&a_{32} \end{vmatrix}&=&0\\&\,&\\ (\lambda-a_{11})\left[ (\lambda-a_{22})(\lambda-a_{33})-a_{23}a_{32} \right] -a_{12}\left[ a_{21}(\lambda-a_{33})-a_{23}a_{31} \right] +a_{13}\left[ a_{21}a_{32} - a_{31}(\lambda-a_{22}) \right] &=&0\\&\,&\\ (\lambda-a_{11})\left[ (\lambda^2-a_{33}\lambda-a_{22}\lambda-a_{22}a_{33}-a_{23}a_{32} \right]+\\ -a_{12}a_{21}\lambda+a_{12}a_{21}a_{33}-a_{12}a_{23}a_{32}\,+\\ +a_{13}a_{21}a_{32}-a_{13}a_{31}\lambda+a_{13}a_{31}a_{22}&=&0\\ \, \\ \lambda^3-\underbrace{\begin{pmatrix}\,\,\,\,\,a_{11}+\\ \,\,\,\,\,a_{22}+\\a_{33}\end{pmatrix}}_{\text{Trace}A}\lambda^2+\begin{pmatrix} \,\,\,\,\,a_{22}a_{33}-a_{23}a_{32}+\\ \,\,\,\,\,a_{22}a_{33}-a_{23}a_{32}+\\ a_{11}a_{33}-a_{13}a_{31} \end{pmatrix}\lambda\underbrace{-\begin{pmatrix} -a_{11}a_{22}a_{33}+a_{11}a_{23}_a_{32}\\ +a_{12}a_{21}a_{33}-a_{12}a_{13}a_{31}\\ -a_{13}a_{21}a_{32}+a_{13}a_{22}a_{31} \end{pmatrix}}_{\det{A}}&=&0 \end{array}](https://www.samartigliere.com/wp-content/ql-cache/quicklatex.com-6fa593189e99c233bc8d1f628b15c819_l3.png "Rendered by QuickLaTeX.com")